Category: website2.0

The NFDI4Ing base services.
Measure S-5
Overall NFDI software architecture – data security and sovereignty
Measure S-5: Overall NFDI software architecture
The goal of this measure is to establish best practices for securely providing and accessing (meta)data in a distributed architecture operated by service providers from different scientific communities. Some examples for these so called data spaces are being implemented by the International Data Spaces Association, Gaia-X or EOSC. The tasks of this measure consider the following topics: Authentication and authorisation infrastructures (AAI), role management, data space interfaces, connectors as well as data identifiers and discovery.
Key challenges and objectives
The services established within this task area but also the activities within other task areas will eventually contribute to the overall vision of the NFDI. To achieve this goal, all offered services should be based on common grounds following consolidated practices. The objectives are widely aligned with the tasks:
1. Find common core for authentication and authorization infrastructures
2. Develop and deploy a role and access management service
3. Develop common interfaces and marketplaces within the federated dataspace
4. Build a linked data space for discoverability
The key challenges are tackled within the Measure and within coordinated activities that work across the different NFDI consortia.
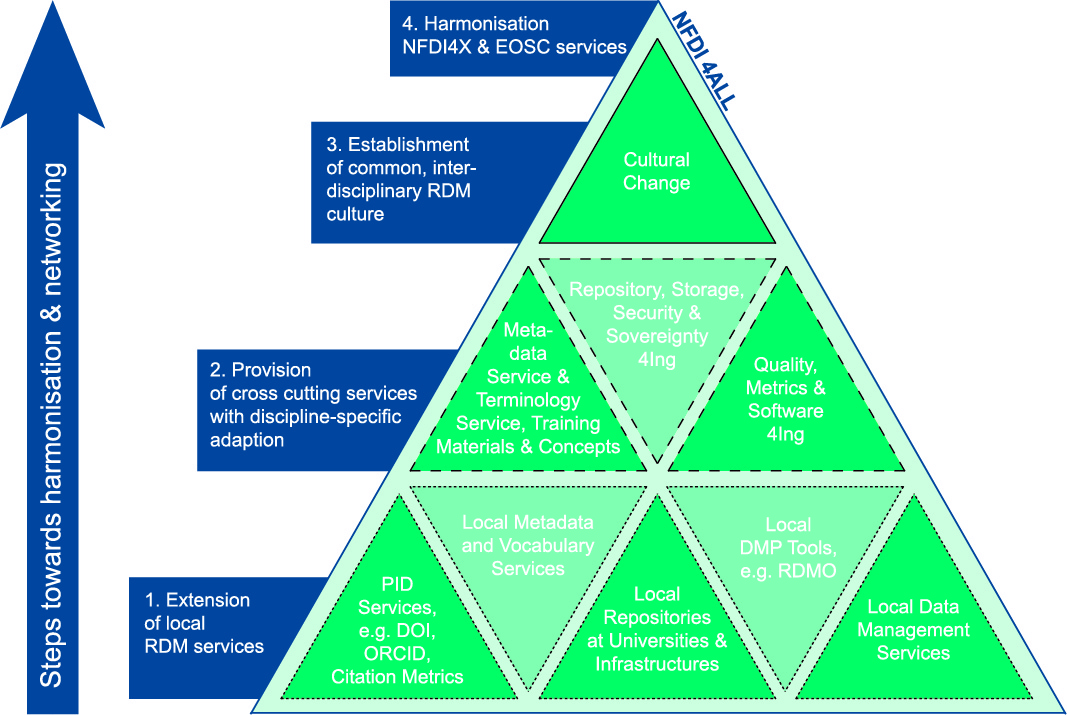
Tasks
Task S-5-1: Harmonisation of authentication and authorisation infrastructures
We will harmonise existing approaches for federated AAIs like DFN-AAI on national, or EDUGAIN on international level, with initiatives such as ORCID that aim at identification of researchers throughout their career at different institutions. If necessary, we combine existing approaches using present reference architectures like AARC. The Work in this task is coordinated with other NFDI consortia in the „Task Force AAI and Rights Management“.
Task S-5-2: Development of a role and access management service
We will develop a role and access management service that uses AAI to identify users and provisions access to other services offered by the federation. Thus, we enable researchers to form workgroups across institutional boundaries. We will implement a service for role and access management that is able to provide access rights to other services within a federation. The task will be coordinated with the BMBF funded project „FAIR Data Space“.
Task S-5-3: Development of interfaces and marketplaces towards a common federated data space
We will define a set of interfaces as a reference architecture of a federated data space for research data that is comparable, or better compatible, with existing interfaces for repository harvesting, linked data interfaces, or the International Data Space. The task will be coordinated with the BMBF funded project „FAIR Data Space“.
Task S-5-4: Building a federated linked data space for discoverability
We will connect decentralised engineering-related (meta)data services and repositories with interfaces and services for data identifiers and discovery mechanisms in a federated data space. The task is carried out in conjunction with S-3 and it will be coordinated with the BMBF funded project „FAIR Data Space“.
Results
NFDI4Ing is active in the NFDI Task Force AAI and contributes to the overall vision of a common authentication infrastructure for the NFDI. Within the BMBF funded project „FAIR Data Spaces“, NFDI4Ing contributes requirements towards connecting FAIR research data services with cloud infrastructures provided by Gaia-X. The projects aims to coordinate the efforts of many NFDI consortia towards a common, cloud based data space.
Contact Information
The measure is lead by:
The NFDI4Ing base services.
Measure S-4
repositories & storage
Measure S-4: Repositories & storage
When accessing or generating data, when analysing or publishing data, engineers are dealing with a huge variety of experimental settings and research circumstances. Besides, the number of research data management solutions is increasing. Different kinds of repositories, storage systems, and recommendations for archiving exist but are not shaped on the discipline specific requirements. For repositories, we distinguish on the one hand institutional repositories (e.g., RADAR, Zenodo, KITopen) and on the other hand community specific repositories (e.g., NOMAD for material sciences). This is a very useful method for publishing research data and can be part of a long-term archiving plan, but the required flexibility for heterogenous data, which is still in the mode of changing and analysis, is missing. Therefore, we provide tools and develop interfaces for integration and interoperability of repositories.
Key challenges and objectives
The heterogeneity of data generation workflows and storage formats poses a challenge to researchers in engineering. Within this measure, it is therefore our goal to define best practices and tools for storage, exchange, and long-term preservation for data of varying quality and volume to foster reusability of research data in this highly decentralised environment.
The objectives are aligned with the tasks:
1. Establishment and maintenance of best practices and recommendations for community specific repositories & storage solutions
2. Development of software for federated storage services
3.Development of a cost and distribution model for storage
Furthermore, the development of storage and repository federations requires a strong involvement in the cross-cutting sections (e. g. Authentication and Authorization Infrastructure (AAI)) of NFDI.
Tasks
Task S-4-1: Establishment and maintenance of best practices and recommendations for community specific repositories & storage solutions
We will compile a catalogue of data formats and storage technologies for engineers considering sustainability, interoperability, and accessibility including a review of suitable technologies. We will deliver recommendations for building new repositories based on the continuous analysis of the state of the art and a collection of existing community specific repositories (to be registered in re3data) and provide tutorials and other training material in cooperation with measure S-6 “Community-based training on enabling data-driven science and FAIR data”.
Task S-4-2: Development of software for federated storage services
We will develop a software stack based on existing solutions that implements repositories, harmonised protocols/interfaces, and best practices for operators of federated storage services that incorporate good scientific practice and the FAIR principles. Considering data storage, the software will take into account data management workflows but also authentication, user management, and access for users from external organisations (in cooperation with measure S-5 “Overall NFDI software architecture – data security and sovereignty”). With the definition in place, we will reach out to existing infrastructure providers to achieve a higher level of standardisation of storage infrastructures for engineering researchers.
Task S-4-3: Development of a cost and distribution model for storage
We will develop a cost and distribution model that allows participating institutions to share storage infrastructures and compensate for costs inflicted by acquisition and operation of the infrastructures when research data is accessed by researchers of the community.
Results
The partners and contributors meet every month virtually to exchange results and information. Available data and metadata storage systems have been compiled and analyzed. The results are now available to the public via the S-4 GitLab repository.
Contact Information
The measure is lead by:

For general information on measure S-4 please contact:
The NFDI4Ing base services.
Measure S-3
metadata & terminology services
Measure S-3: Metadata & terminology services
The definition of metadata and concepts, associated attributes and relations that are readable and understandable, not only to target audiences but also to machines, is key to FAIRness. To address this concern, we will provide services to facilitate the creation, sharing and reuse of subject- and application-specific standardised metadata and their integration into engineering workflows, as well as a Terminology Service to enable researchers and infrastructure providers to access, curate, and update terminologies.
In NFDI4Ing, it is essential that metadata is not only used for documentation and indexing of research data stored in repositories, but also to facilitate tasks such as (automated) retrieval, analysis, or combination of complex research data during active research. As tools for the generation, management, and use of vocabularies and ontologies, we are working on the most suitable tools for reliable management of subject-specific vocabularies.
Key challenges and objectives
The following key challenges have been identified in regard to metadata & terminology services:
1. Support development of metadata with formal semantics that are generic enough to be interoperable but specific enough to represent discipline-specific concepts
2. Help providing (semantic) documentation of all steps of data production and outcome including metadata adjustments, raw data, and intermediate data to describe and predict the behaviour of real and virtual experiments
3. Metadata and ontologies should describe the validation and quality-control processes of research software with a possible focus on simulation software
4. Enable development of suitable vocabularies and schemata to describe the operational function of devices used to collect, analyse, and visualise data generated and/or processed in industrial production workflows
Tasks
Task S-3-1 Tools for standardising metadata based on application profiles
The variability of methods used in engineering implies a constant need to standardise application-specific metadata. Using existing terminologies as well as those provided by the Terminology Service as basis, we will offer a smart interface that allows to find and select suitable terms and assemble them into application profiles. Term suggestions will take into consideration statistics on term usage within the defined schemata and take into account settings for filtering and preference of underlying vocabularies that can be set based on community recommendations. If no fitting term is found, a custom term may be specified as provisional building block, automatically triggering a term request for the Terminology Service. To ensure that schemata are shared and reused, a connected repository will archive and index the schemata as well as make them available for reuse and adaptation. While the metadata schemata will be defined within the task areas that require them, information experts from metadata services will support the scientists collaboratively. They also assist in developing tools for integration of metadata standards into scientific workflows (e.g. harvesters for extracting metadata from available sources like file-headers, log files, software repositories and tools for quality control of metadata).
Task S-3-2 Terminology Service
The Terminology Service (TS) will enable the development of subject-specific terminologies, simultaneously fueling application profiles with terms and using the application profiles as a basis for refining formal ontologies for the archetypes. The terminology service will provide technical infrastructure for access, curation, and subscription to terminologies, offering a single-point-of-entry to terminologies. A RESTful API will provide access to terminologies in a uniform way regardless of their degree of complexity. The Terminology Service will allow the handling of requests such as custom terms for new terminologies or updates of existing terminologies by stakeholder communities based on a ticket-based help-desk. The service will include transformation tools from textual and tabular documents into semantic formats, a linked data interface and terminology integrity checks and validation. The Terminology Service will enable semantic terminology subscription and notification to recognise new matching terminologies according to the specifications of a user, activate defined processing of the terminology if requested, and inform subscribers by email about new terminologies or recent changes.
Task S-3-3 Metadata Hub
We will provide a repository for publishing the (full) metadata sets describing actual research data according to the application profiles and ontologies. This metadata hub will enable highly specific queries that can be used to access research data stored in repositories that do not support the full scope of the supplied metadata. The use of DOIs enables the linking between all components of the research process incl. experiments, raw data, software, subject-specific metadata sets, and the tracking of usage and citations. This task will also enable applications that require analysis of metadata. Applications include data-level metrics and provenance tracking based on published metadata sets as well as extraction of statistics on term frequencies fuelling the smart interface of the standard generator for application profiles. To demonstrate the common core and compatibilities of the different Metadata Hub implementations, a common frontend and REST interfaces “Turntable” will be implemented. This will demonstrate that not only concepts are shared between different implementations but that they can actually serve common use cases.
Results
In Task S-3-2 we are currently working on a first version of the Terminology Service, based on the Open Source Software Ontology Lookup Service (OLS) from EBI, which will also be the central entry point for the Terminology Service. This first version is expected to be open for public testing in May 2021.
Contact Information
The measure is lead by:
Felix Engel
The NFDI4Ing base services.
Measure S-2
Research software development
Measure S-2: Research Software Development
Many scientific workflows are governed by algorithms written in software codes. Therefore, software is an important type of research data in its own right in the engineering sciences. It is thus important to build RDM services that take the special properties of research software into account.
Key challenges and objectives
The key challenges of the base services measure S-2 are:
1.Integrate with existing environments for software based experiments (Jupyter, Schedulers)
2.Make workflow runner infrastructure available to researchers
3.Provide a catalog of workflows and workflow steps for quality assessement and RDM processes
A particular computer experiment is usually represented by a snapshot in time, with respect to the state of the source codes and scripts employed as well as the operational environment it is executed on. Replicability guarantees that a software-driven computer experiment, repeated in the same operational environment, produces the same results. Reproducibility, on the other hand, ensures that a software-driven computer experiment can be repeated in a different context. As also outlined in the challenges for the archetype BETTY the situation is particularly complex in engineering, as many different programming languages are employed, often within the same computer experiment (e.g. python scripts for orchestration of simulations that are written in C++, C and FORTRAN). The actual execution environment of a piece of software is also affected by issues such as the hardware platform (e.g. accelerators of various flavors), libraries, the operating system, and compilers.
The goal of this measure is to provide services and best practices that allow researchers to combine RDM and enterprise-grade software development workflows.
Tasks
S-2-1 Infrastructure for replicable and reproducible software based experiments
We will set up reusable workflows, e.g. script-based, that relate source codes, experimental setups, and data processing routines. Best-practices in continuous integration, arising, for example, from the activities of measure B-1 will be standardised, documented and continually assessed, in particular with respect to version control, automated testing, deployment, and linking to publication records.
We will make them usable not only for highly-skilled software developers, but also for the large number of researchers without a background in software engineering. We employ and assess container solutions such as Singularity for packaging up simulation experiments. We will closely collaborate with measure B-3, emphasising generality of usability as well as enhanced awareness of these platforms of HPC environments and their requirements on performance and emulation of hardware features. Finally, we will deploy, in collaboration with measure B-3, a JupyterHub server to lower further the threshold for new users.
S-2-2 Services for the assesssment of the quality of software created by engineering researchers
Templates and best practice examples will be made available that allow to create quality metrics to make sustainability and reusability of source codes tangible for researchers using existing enterprise grade solutions. Based on existing continuous integration software, we create a service that can be used by engineering researchers for continuous and automatic generation of quality metrics to enhance their software during development and for judging the quality of existing codes before they are being reused. We will connect quality metrics with RDM workflows to extract additional metadata from existing source codes or documentations to make RDM tasks like publishing easier for engineers.
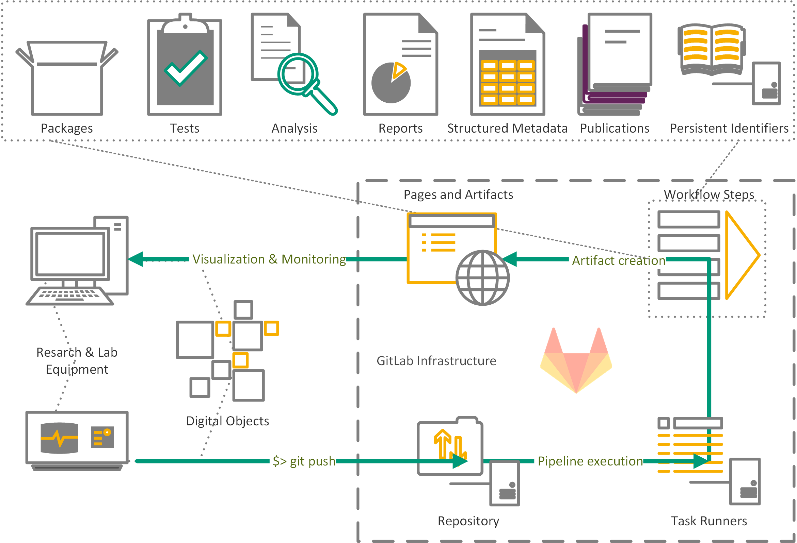
Results
In Task S-2-1 we are currently building a knowledge base consisting of short articles that describe how to set up the different aspects of a modular workflow, based on the experiences made in the context of SFB1194. These articles cover, for example, containerization, automated testing, deployment, and cross-linking of publication, data and code. The knowledge base currently can be accessed via https://tuda-sc.pages.rwth-aachen.de/projects/nfdi-4-ing-kb/.
To test and further improve this knowledge base we initiated a collaboration with the group Hydraulic Engineering from Civil and Environmental Engineering Department at TU Darmstadt in the context of OpenFOAM-based modelling of heat transfer in streams.
In Task S-2-2 two introductory Workshops were organized in conjunction with FDM.NRW in December 2020 and April 2021. The workshops will be continuously offered on approximately quarterly to semi annual basis. Future workshops will be announced on the webpage of FDM.NRW (https://www.fdm.nrw). Workshop materials are available on GitLab.com (https://gitlab.com/gitlab-nrw-workshop-2021-04) under CC-BY-SA 4.0 license.
We built a demonstrator for assesment and reporting of RDM KPIs as Schedules build on top of the GitLab infrastructure provided by NFDI4Ing (https://git.rwth-aachen.de and https://git-ce.rwth-aachen.de). Both instances can be accessed by researchers from the engineering community. Current work focusses on making workflow steps and infrastcutures more widely available.
Contact Information
The measure is lead by:
The task leads are:
The NFDI4Ing base services.
Measure S-1
Quality assurance in RDM processes and metrics for FAIR data
Measure S-1: Quality assurance in RDM processes and metrics for FAIR data
In this measure, we develop a framework to provide standards, metrics, and guidance for the organization of data curation. The framework incorporates existing best practices and the FAIR data principles. We begin with creating a common research data management maturity model and special models for each of the NFDI4Ing archetypes.
One important and well-established tool for quality assurance in RDM is data management planning (DMP). Within the measure, the development of an open source Research Data Management Organiser (RDMO) software and a DMP service are being carried out. Archetype and sub-discipline-specific DMP templates are being created, and we investigate how to support researchers and local RDM offices by designing a DMP review service based on the respective maturity level.
For the FAIRness of engineering data, management metrics and key performance indicators are being developed. The metrics and identifiers are based on certain recognized and operationalized goals and form the basis for a self-assessment at the institutional level, which subsequently can be utilized to track performance, benchmark RDM performance comprehensively, and impose RDM by performance incentivisation.
Key challenges and objectives
The purpose of measure S-1 is to assist and support researchers in organizing and self-monitoring research data processes to ensure and control data quality. All archetypes and communities rely on data quality assurance processes, the respective tools, and data quality metrics to make their data FAIR and to enable engineers to appraise and select data for further curation.
To assure data and process quality, a commonly agreed set of criteria will be defined that is valid not only for the engineering community but for the scientific community as a whole.
Tasks
The measure S-1 includes four tasks.
Within the scope of the Task “Development of research data management maturity models”, a model for the organization of research data management processes is being designed. Depending on the type of the research project, the model can be used for self-control in small research projects or for the management of large projects to organize and motivate work with research data in and between subprojects.
The purpose of the Task “Data management planning with RDMO” is to organize and support the planning by means of RDMO software. It provides a highly adaptable user interface, authorization procedures and customizable DMP templates, which allow an effective and easy collaborative data management planning in multi-institutional research projects.
The task “Fostering DMP templates in engineering” designs, examines and evaluates archetypes and sub-discipline specific DMP templates for different stages of research projects as well as in close collaboration with all archetypes and community clusters.
Within the task “Providing and utilizing FAIR data metrics” FAIR data metrics and KPIs relevant to the FAIRness of the engineering data are being identified concerning general and already established research performance KPIs. Finally, a FAIR key-figure system will be developed. This will be done in close collaboration with CC41 to ensure participation in the author-critic cycle and acceptance in the engineering community.
Results
RDM Framework
The RDM Framework and Maturity Model under development is a tool for control and self-monitoring to provide a set of recommendations to achieve the quality level of data management processes and the quality level of data. The first version takes into account the basic process characteristics of certain research projects and processes specific for archetypes (see Fig. S-1). These processes are assigned to generic and specific goals and define the degree to which a set of characteristics of data fulfills requirements and which will be described and achieved by best practices, self-control criteria, checklists and metrics.
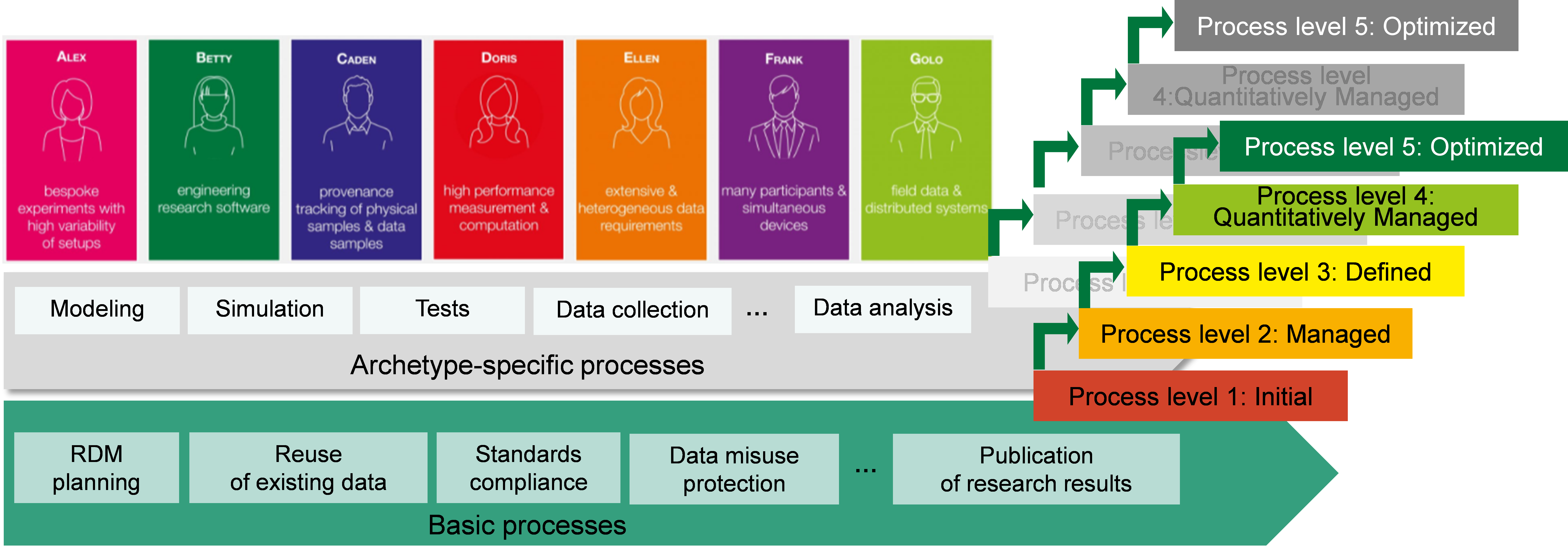
Implementation of data management planning with RDMO
An establishment of an NFDI4Ing client in RDMO and the possibility to create data management plans for every researcher with DFN-AAI identification are realized and an engineer-specific guide for data management plans is developed.
More information: https://rdmorganiser.github.io/
Contact Information
The measure is lead by:

The task leads are:
RDM maturity models
DMP with RDMO
DMP templates in engineering
FAIR data metrics
The NFDI4Ing BASE SERVICES.
Developing and maintaining RDM services
The task area base services, bundles all basic NFDI4Ing RDM services – both existing and those in development. As such, it provides central services for the archetype task areas in order to address their specific requirements. In the same spirit, the task area is in close contact with the Community Clusters to pick up on requirements and needs of the larger engineering community. The base services are designed to support the strong interdependencies between different measures and to foster a development mentality focussed on interlocking and consolidating efforts between individual NFDI4Ing partners. Each measure is worked on by multiple partner institutions with a defined lead. Each staff member of the task area participates in at least two measures to support and further develop a holistic view on the service portfolio.
NFDI4Ing builds all of its services in a modular and user-centred style. The key objective of the task area Base Services is to further develop and scale solutions provided by the archetypes and supply specific services and tools for internal and external partners. Initially, we have identified seven service objectives that are relevant for all engineering archetypes and communities and thus form the individual measures of the task area Base Services:
Quality Assurance & Metrics (S-1)
All archetypes and communities rely on data quality assurance processes, the respective tools, and data quality metrics to make their data FAIR and to enable engineers to appraise and select data for further curation (measure S-1).
Research Software Development (S-2)
The support for research software development is by now urgent in all fields of engineering, particularly but not only in computational engineering (measure S-2).
Metadata & Terminology Services (S-3)
Providing easy-to-use yet comprehensible metadata tools for the engineering research daily routine as well as establishing detailed terminologies for engineering are the common ground for all RDM processes (measure S-3);
Repositories & Storage (S-4)
The safe and secure storage and long-term archiving of data as well as the possibility to share or publish data in suitable repositories is relevant to all archetypes and communities, yet in varying shape (measure S-4).
NFDI Software Architecture (S-5)
All NFDI4Ing services participate in are part of an overall software architecture incl. authentication, authorisation, and role management schemes, which is absolutely necessary for confident data from research projects close to industry (measure S-5);
Community-based Training (S-6)
Scientists of all disciplines are able to retrace or reproduce all steps of engineering research processes. This ensures the trustworthiness of published results, prevents redundancies, and contributes to social acceptance.
Automated Data & Knowledge Discovery (S-7)
Most of the outcomes of engineering research is still hidden in human-readable publications only. Making engineering data FAIR needs advanced techniques of data extraction from and knowledge discovery in the engineering literature (measure S-7).
All NFDI4Ing services are designed as open, modular, and standardised as possible, in order to foster crossconsortial reusability. Furthermore, we strive for technical and structural connectivity to parallel and prospective developments in RDM on the national and international level (e.g. in the EOSC).
News & events from NFDI4Ing -
Research Data Management in engineering
General Infos
Here you can find the latest updates on NFDI4Ing as well as an archive of previous news and newsletter entries and past events.
News
News
A new publication discusses possible future roles of Data Management Plans (DMPs), templates, and tools in the upcoming NFDI service architecture. This position paper summarises ideas developed and collected during interdisciplinary workshops of the Data Management Planning Working Group (infra-dmp),
Last year, we invited the engineering communities to topical community meetings, six in total. Starting with 2024, we switch from topical to "arche-topical" community meetings, representing the NFDI4Ing archetypes. We kick things off with BETTY, our archetype focused on engineering
To fight the reproducibility crisis in science, the NFDI4Ing task area ALEX is developing PlotSerializer - a Python package for serializing scientific diagrams from popular libraries like matplotlib to json.
The NFDI4Ing Metadata Profile Service is a platform that facilitates creation, curation and sharing of metadata profiles. The profiles are based on the W3C recommendation SHACL and can be created in a graphical user interface by selecting suitable terms from
Ideally, researchers can incorporate existing, established and tested research software into their own work. BETTY tries to help researchers in finding existing software suitable for their needs, developing new software, and publishing software artifacts in a sustainable and reproducible way.
Upcoming events
Upcoming events
The NFDI4Ing Community Meeting focused on our archetype ELLEN will take place June 6th, 2024.
On July 25th a NFDI4Ing Community Meeting will focus on the challenges, solutions and services of our archetype FRANK, who mainly works in Mechanical and Industrial Engineering and with heterogeneous data sources.
The NFDI4Ing conference 2024 will take place on the 18th & 19th September as a virtual event. The call for proposals is now open!
News archive
In our base service “Repositories and Storage” (S-4) we have reached a couple of milestones during the last year, with many new developments in the storage and repositories domains.
The base service "research software development" provides infrastructure, best practices and templates to make research software and its development more replicable and reproducible while improving the quality of the written code. Currently, our main projects are a JupyterHub server for
The base service “Quality assurance in RDM processes and metrics for FAIR data” in NFDI4Ing includes the support of data management plans with RDMO, the development of maturity models for research data management processes and the provision and maintenance of
By ordering the RDM activities based on their occurrence in the engineering research process, Jarves provides a structure for RDM in engineering. Based on the research’s boundaries, Jarves offers information on the next steps and available tools.
SciKGTeX enables authors to create “FAIR-by-Design” publications by enriching them with FAIR information once and in parallel to the time of creation. This information is embedded into the PDF’s XMP metadata for persistent and long-term availability.
Past events
The next NFDI4Ing Community Meeting of the materials science and engineering community will take place in a virtual format on Friday, 08 December.
The next meeting of the SIG QA&metrics is on 8 December at 09:00. By the end of the year, the current results of the SIG (DMP, FAIR, Quality dimensions) will be summarised and new topics for the upcoming meetings will
On November 23rd & 24th, the TU Darmstadt hosts the OPEN STRUCTURES conference on data, tools and cultures in research. The conference can be attended free of charge.
The next NFDI4Ing Community Meeting of the heat and process engineering community will take place in a virtual format on Friday, 27 October. The meeting will focus on the data lifecycle and data management plans.
In this Workshop, Prof. Pelz provides examples of how data literacy is integrated into the Mechanical Engineering - Sustainable Engineering bachelor's degree program at Darmstadt University of Technology. Read more...
Feb. 27: Community Meeting on research software
The first NFDI4Ing Community Meeting of the calendar year will take place on February 27, 2024. The event is aimed at scientists from all communities who are interested in research software. We want to introduce you to innovative tools, services and methods that make it easier for you to find, use and develop research software and handle the associated data and metadata.
learn more
Previous slide
Next slide
Welcome to NFDI4Ing – the National Research Data Infrastructure for Engineering Sciences!
Education, Services, Guidelines
As part of the German National Research Data Infrastructure (NFDI), we provide services, educational material and guidelines for research data management, specifically for researchers working in engineering.
The NFDI4Ing archetype concept.
Structuring challenges in engineering RDM
From its inception, NFDI4Ing opted for a methodical and user-oriented approach to meet the requirements of the engineering sciences (research areas 41-45 according to the DFG classification 2016-2019 [only available in German]). In this heterogeneous community of highly specialised research (sub-)areas, a vast number of individualised approaches and extremely focussed tools and applications have been developed. Primarily due to their often lacking modularity, these tools and approaches can rarely be reused or applied to new problems by engineering research groups with similar, yet slightly different requirements. Additionally, the tools and applications are often not sustainable and easily outdated from the point of IT progress or new scientific demands. We consider this to be highly inefficient. In NFDI4Ing, we decided to lay ground for a systematic solution of this challenge by developing a new solution design: the archetype concept.
To identify the specific needs of the engineering science community, we used a mixed-method approach including the collection of qualitative and quantitative data. Since 2017, we conducted semi-standardised face-to-face interviews with representatives from the five DFG research areas of interest and a number of workshops with different foci, each reaching from 12 to 50 attendees.The objective of this exploratory phase was to provide a broad overview of the current state and needs regarding research data management (RDM) in the engineering sciences. Based on this data, we developed 24 key dimensions for describing engineering science as morphological box, a heuristic problem solving method e.g. used for the development of product innovations. Then, this morphological box was used in the structuring process to categorise individual researchers according to their respective characteristics and to identify our most important target groups in terms of prototypical engineering scientists or methodological archetypes. In total, we derived seven archetypes being representative for the majority of the engineering sciences and derived method oriented task areas from each of these archetypes:
• Alex: bespoke experiments with high variability of setups
• Betty: engineering research software
• Caden: provenance tracking of physical samples & data samples
• Doris: high performance measurement & computation
• Ellen: extensive and heterogeneous data requirements
• Frank: many participants & simultaneous devices
• Golo: field data & distributed systems
These archetypes define typical research methods and workflows classifying corresponding challenges for research data management. So, engineers will be reached via their identification with the methodological archetypes. You can find further information on each archetype on their respective profile pages linked below.
NFDI4Ing is and will continue to put emphasis on the identification and harmonisation of engineering research archetypes. Therefore, we are aiming to continually evaluate whether our community of interest (still) feels represented by the deduced archetypes. In a first step to this end we conducted an online survey in mid-2019. This method allowed approaching and involving a significant number of engineering scientists. The survey consisted of two parts: (1) RDM-related questions and (2) evaluation of the archetypes. We used an extensive mailing list including engineering research associations and other potential disseminators to achieve a reasonable sample size. Thus, we reached engineering research groups at all German universities and universities of applied sciences, as well as at all nonuniversity engineering research institutions (e.g. Fraunhofer institutes, Helmholtz centres, governmental research institutes, etc.). In total, 618 engineers completed the survey (each representing one research group from all fields of engineering), providing a solid basis for evaluating our approach.
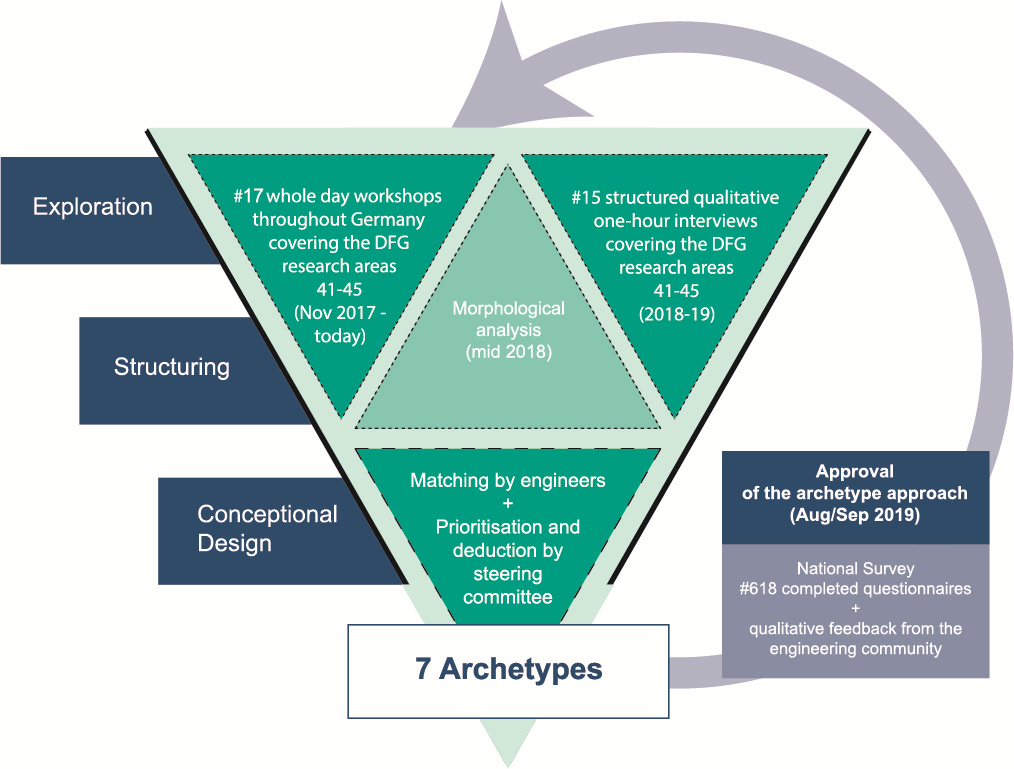
Illustration of the exploration, structuring and conceptual design of the archetype system
Analysis of the survey data confirmed the representativeness and relevance of our seven archetypes: 95% of all research groups identify themselves with at least one archetype. The typical engineering research group combines elements of three to four archetypes and considers on average two archetypes as very relevant, showing a good division of demands by the archetypes. These findings are mostly independent of the engineering sub-discipline. These conclusions are further supported by the aforementioned interviews and workshops giving valuable qualitative feedback regarding our method-oriented and user-centred approach.
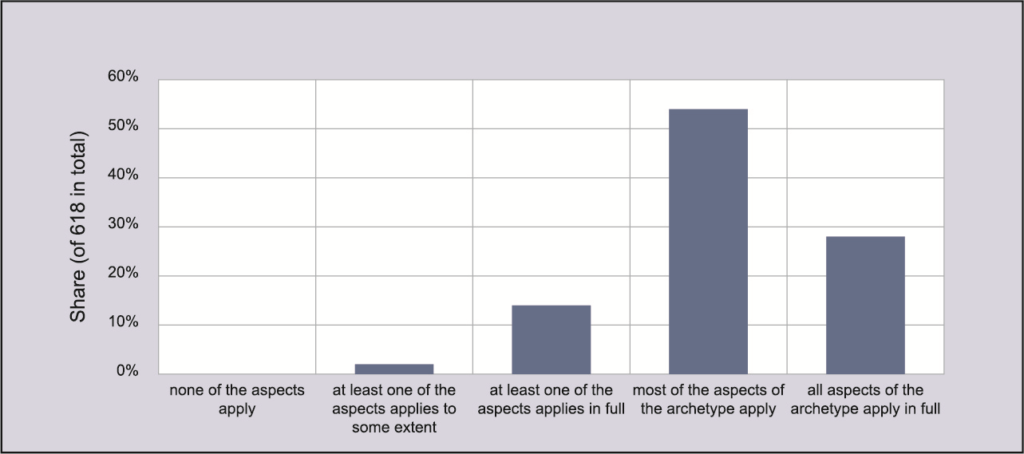
Survey results - Degree of identification of the respondent research groups with the archetypes
We are deeply committed to keeping up to date with the developing needs and demands in RDM in the engineering sciences. With our Community Clusters we try to establish a consistent dialogue between the consortium and the individual engineering research areas – both for sharing results and best practices, as well as to stay current on the developements and requirements of the engineering sciences. Via our seed funds programme we offer funding for innovative ideas and projects that further develop our work programme. Should the need arise, we are always open to modify our archetypes (or even add a new one).

The archetype concept.
Introducing the
archetype:
Betty
Hello, I’m Betty.
I’m an engineer and self-taught programmer that develops research software. Very often, this software represents a computational model for the simulation of an engineering application. For validating such a model, I have to compare my results with data such as other simulation data or experimental observations. For this and other purposes, I also write code for analysing and converting research data. My software usually has a lot of dependencies in form of the operating system and third-party libraries. While I’m very keen on guaranteeing the reproducibility of my computational results, I can’t dedicate too much working time to achieve this. My professional background can be located in any engineering discipline.”
I use individual combinations of software, apparatus, methods, and interfaces that vary from case to case. Flexibility is particularly important to me, which makes it all the more important that I can trace the configuration and data flow in my experiments at any time. I am solely responsible for my experiments and need to know exactly what my system is doing. My professional background may be based in production enginering, constructive mechanical engineering, thermofluids, energy systems, systems engineering or construction engineering.”
As defined here (PDF), “research software (as opposed to simply software) is software that is developed within academia and used for the purposes of research: to generate, process, and analyse results. This includes a broad range of software, from highly developed packages with significant user bases to short (tens of lines of code) programs written by researchers for their own use.” In the task area Betty we address this whole range of software, and in particular the fact that it is usually developed by domain specialists rather than software engineers. While research software certainly is research data, it exhibits particular characteristics compared to more “conventional” data. This yields the following challenges:
1. Code inside a research software project that is under continuous development is subject to permanent change. Employing version control is mandatory to keep track of changes and to provide means to refer to a particular code instance.
2. Any particular piece of research software often exhibits complex dependencies on other software such as third-party libraries and operating systems, as well as possibly on the hardware architecture on which the software is supposed to be executed.
3. The broad variety of engineering applications is reflected in a huge number of engineering research software projects exhibiting very different scope, size, quality etc. This demands correspondingly adaptable RDM processes and tools.
4. Engineering research software is often dedicated to numerical simulation. To ensure the quality of the software, the underlying model needs to be validated, which in turn usually requires the comparison of simulation results with other data. Analogous validation requirements hold for other types of software such as software for systems control.
5. Software itself generates data in form of computational results. While the results are commonly discussed in a scientific publication, a proper RDM strategy for research software should aim for ensuring the reproducibility of these results.
A broad range of tools already exists to tackle several technical challenges listed above. The fundamental challenge within this task area rather is to offer the engineering community a consistent toolchain that actually will be employed in daily engineering research. From these key challenges and our common goals, we identify three key objectives for this task area. In particular, we would like that every engineer:
1. can be equipped with the tools and knowledge that are necessary and useful to develop validated, quality-assured engineering research software.
2. is able to guarantee the reproducibility or at least the transparency of his computational results and to provide his peers with usable solutions for the actual reproduction.
3. can easily equip his own engineering research software and validation data with standardised metadata and find such software and data of others for his research.
We implement five measures to achieve the abovementioned goals. Measures B-1 and B-2 target primarily the first goal, measure B-3 the second, and measures B-4 and B-5 the third one:
B-1 – Integrated toolchain for validated engineering research software: Several solutions for individual RDM measures in the context of software already exist. By integrating these tools, we will implement and support a consistent toolchain for developing validated engineering research software.
B-2 – Best practice guides and recommendations: We aim to design best practice guides and recommendations for developing engineering research software by means of the toolchain that results from the tasks of measure B-1, starting from the first lines of code to the provision of web frontends and backends for the reproduction of computational results.
B-3 – Containerisation and generation of web frontends: We focus on two main ingredients to achieve our second goal of enabling every engineer to guarantee and facilitate the reproducibility or at least the transparency of computational results: containerisation and generation of web frontends. With Docker and Singularity regarding containerisation as well as JupyterLab concerning web frontends, the technical tools are readily available.
B-4 – Standardisation and automated extraction of research software metadata: Up to now, no standardised metadata format for engineering research software has emerged. CodeMeta defines subsets of the schema.org vocabulary as possible entries for the description of software. However, it is discipline- and even research-agnostic and doesn’t include any engineering-related entries such as the software’s application areas or details on a computational model. On the other hand, there exist recent efforts (ArXiv) on metadata formats for engineering sciences with no particular focus on software.
B-5 – Catalogue of engineering research software and validation data: In order to help an engineer to find software that is supposed to be capable of solving his current research question, we aim to establish a catalogue of engineering research software and related validation data.
In the scope of this task area, we are planning to realise the abovementioned sustainability measures within three pilot use cases in collaboration with partners from different fields of engineering sciences. In turn, feedback from these use cases will allow us to refine the needs and demands that originate from different engineering disciplines, and to adjust the recommended measures accordingly.
We have recently completed the project descriptions of the pilot cases, which cover the following topics:
– Application of workflow tools to represent, share and publish scientific workflows: an evaluation of the requirements, a selection of tools, and best practices on how to use them. We have initiated a Git repository in which we will document our findings and experiences, open for contribution by the scientific community. Besides this, we aim to initiate a Special Interest Group on the topic.
– Software quality assurance for projects distributed over several code repositories, where downstream code repositories have to be tested against changes in upstream code repositories.
– Automated and continuous testing of simulation frameworks against remotely-hosted and possibly version-controlled reference/benchmark solutions to guarantee that the code produces physically meaningful results.
Moreover, we are in the process of developing an abstract model for the description of software-driven scientific workflows. On the basis of this model, we can define adequate metadata schemes for their description in a machine-readable format.
The task area is lead by:


For general Information on Betty please contact:
