introducing the archetype Doris
“Hello, I’m Doris! I’m an engineer conducting and post-processing high-resolution and high-performance measurements and simulations on High-Performance Computing systems (HPC). The data sets I work with are extremely large (hundreds of terabytes or even petabytes) such that they are, by and large, immobile. They are too large to be copied to work stations and the (post-) processing of the experimental and computational data generally is done on HPC systems.
The HPC background mandates tailored, hand-made software, which takes advantage of the high computational performance provided. The data sets accrue in the combustion, energy generation and storage, mobility, fluid dynamics, propulsion, thermodynamics, and civil engineering communities.”

key challenges & objectives
Engineers rely on high-fidelity, high-resolution data to compare their novel modelling approaches in order to verify and validate the proposed method. The data sets from HPMC projects are often used as reference (benchmark) data for modelers and experimentalists. Data accessibility and ensuring reusability for other research groups in order to validate their modelling approaches and their chosen methods can be a valuable progress and an opportunity for new, data based research workflows.
Doris faces the key challenge that data from high-performance measurement and computation (HPMC) applications, which form the base of publications, are not accessible to the public or the research community. In order to gain access to the data as a third-party researcher in the current setup, one has to contact the research group that generated the data and has to figure out a method to access or obtain the data, which are generally way too large to be copied to work stations.
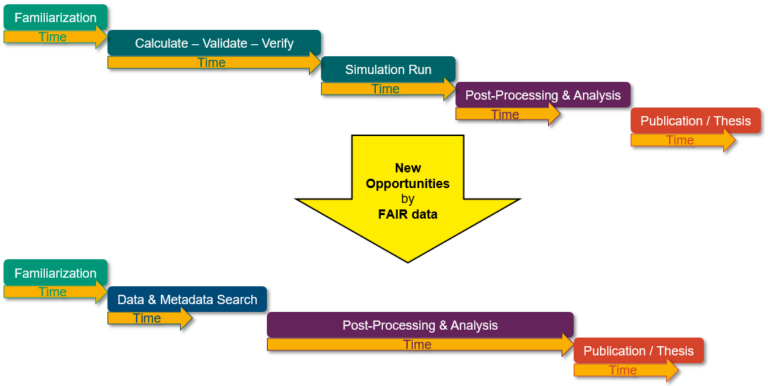
The data neither are documented nor are metadata sets available, as the semantics for HPMC in the engineering sector still need to be adapted to HPMC applications. Common search algorithms and local repositories will be able to find metadata-like keywords in the publications. Data DOIs are supplied to smaller data sets in connection with the publications’ DOI. The multitude of data formats, hardware and software stacks at the different HPC centers further complicate the effective usage of the huge data sets.
The sophisticated HPC background mandates tailored, hand-crafted software, such that a coherent terminology and an interoperable (sub-) ontology have to be established (e.g. in our SIG Metadata & Ontologies and the Base Service S-3). The very specific hardware and software environment at HPC systems makes it time-consuming to get effective access to the data. Therefore, HPC centers need to design new access and file sharing models in order to enable an unhindered opportunity for providing, accessing and post-processing HPMC research data for the community. Software modules simplifying access to the data, and maximizing IO-speeds for the large data sets on the specific platforms will be developed and provided to the community.
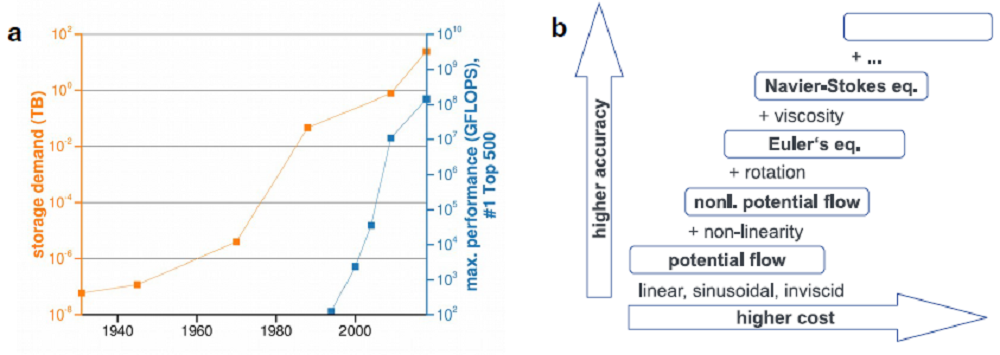
Reproducibility of data beyond the life cycle of HPC systems is still an open issue as software container performance is currently too low to be able to reproduce HPC results in an acceptable time frame. Doris will test and compare the performance and feasibility of different containerization tools along with HPC centers.
Showcase software modules for post-processing algorithms will enable other research groups to speed up the time needed to get a start on reusing the single large data sets. Access to the data stored at the HPC centers for non-HPC customers will be realized. The future widespread accessibility of these unique data sets will further spur machine learning, neural network and AI research on these complex engineering problems fostering the effort to acquire knowledge from data.
measures
The Doris team is working on several key objectives to achieve the objectives for a FAIR data management within HPMC research data.
Accessibility and access rights, data security and sovereignty New user models to reuse very large data sets are being developed and supported by new or adjusted software, for instance to extract and harvest metadata, to post-process simulation or measurement data and to replicate data via containerization tools. Corresponding front ends, interfaces and documentations have to be provided in collaboration with infrastructure participants like LRZ, HLRS and JSC, as well as appropriate access rights, security and sovereignty mechanisms and a (creative commons) license system.
Support for third-party users & community-based training, provision of post-processing algorithms and modules To increase the acceptance of and the contribution to the developments created in NFDI4Ing, tutorials and workshops will be provided to the community along with the project progress and software development. Existing tools will be evaluated and adjusted to facilitate data provision, access and reuse for primary scientists as well as third-party users. Support and training will be supplied in close coordination with base services and community clusters.
Metadata definitions & terminologies, support to data-generating groups For HPC users, not only the physical relevant parameters and procedures have to be included in the metadata, but also information on how the data were exactly generated (exact specifications of the numerical method, boundary conditions, initial conditions, etc.). To reach maximum performance on the HPC systems, vendor-specific software on many levels (IO, optimization directives and procedures, memory-specific access, etc.) as well as special programming techniques are used. Together with the task area Base Services S-3, we will develop metadata standards, terminologies and a sub-ontology, enabling other researchers to find, interpret and reuse the data. In cooperation with pilot users, best-practice guidelines on metadata and terminologies are getting compiled.
Storage & archive for very large data Along with the involved service and infrastructure providers, methods and capabilities will be developed to store and archive these large data volumes. In accordance with Base Service S-4 “Storage and archive for very large data” front-end solutions will be implemented, providing searchable and accessible metadata information together with persistent URLs and DOIs.
Reproducibility on large-scale high-performance systems Reproducibility on large-scale and unique high-performance systems is an unsolved problem. Unlike in experiments, a standard is missing that would describe the level of reproducibility, which in turn may depend on the hardware and software platforms used. This conflict will be addressed defining minimum standards for reproducibility issues. Together with the system providers and pilot users, the efficiency of software containers will be evaluated for HPC environments. Best practice guidelines for reproducibility will be developed and published for HPMC users.
results
Updates and invitations to future workshops and training tools will be communicated through our newsletter and on the NFDI4Ing website. A special domain for training and support tools will be created along with Base Services (particularly in S-6: Community-based training on enabling data driven science).
Software tools will also be provided on the NFDI4Ing website or through GitLab/GitHub. As first results, a metadata crawler for HPC jobfiles and a HPMC-(sub)ontology can be expected.
contact information
The task area is lead by:
Prof. Dr.-Ing. Christian Stemmer
Weblink
christian.stemmer@tum.de
For general inquiries about the DORIS archetype, please contact:
info-doris@nfdi4ing.de
Members of the Doris-Team are:
Benjamin Farnbacher
Technische Universität München
Aerodynamics and Fluid Mechanics
benjamin.farnbacher@tum.de
Friedrich Ulrich
Technische Universität München
Aerodynamics and Fluid Mechanics
friedrich.ulrich@tum.de
Vasiliki Sdralia
Technische Universität München
Aerodynamics and Fluid Mechanics &
Munich Data Science Institute
vasiliki.sdralia@tum.de
Dr. Christine Wolter
Technische Universität München
University Library
christine.wolter@ub.tum.de
Dr. Nadiia Huskova
High-Performance Computing Center Stuttgart
nadiia.huskova@hlrs.de
Dr. Stephan Hachinger
Leibniz Supercomputing Centre
stephan.hachinger@lrz.de
Johannes Munke
Leibniz Supercomputing Centre
johannes.munke@lrz.de
Dr.-Ing. Esther Mäteling
RWTH Aachen
Chair of Fluid Mechanics and Institute of Aerodynamics
e.maeteling@aia.rwth-aachen.de