TUstorage provides machine readable open access research literature for text and data mining projects. The documents can be downloaded individually via its web interface or automatically via an API with no registration required. Each article is tagged with the DDC subject groups of the parent journal taken from the Zeitschriftendatenbank. This provides a basic thematic filter option. Currently, the repository is in test operation.
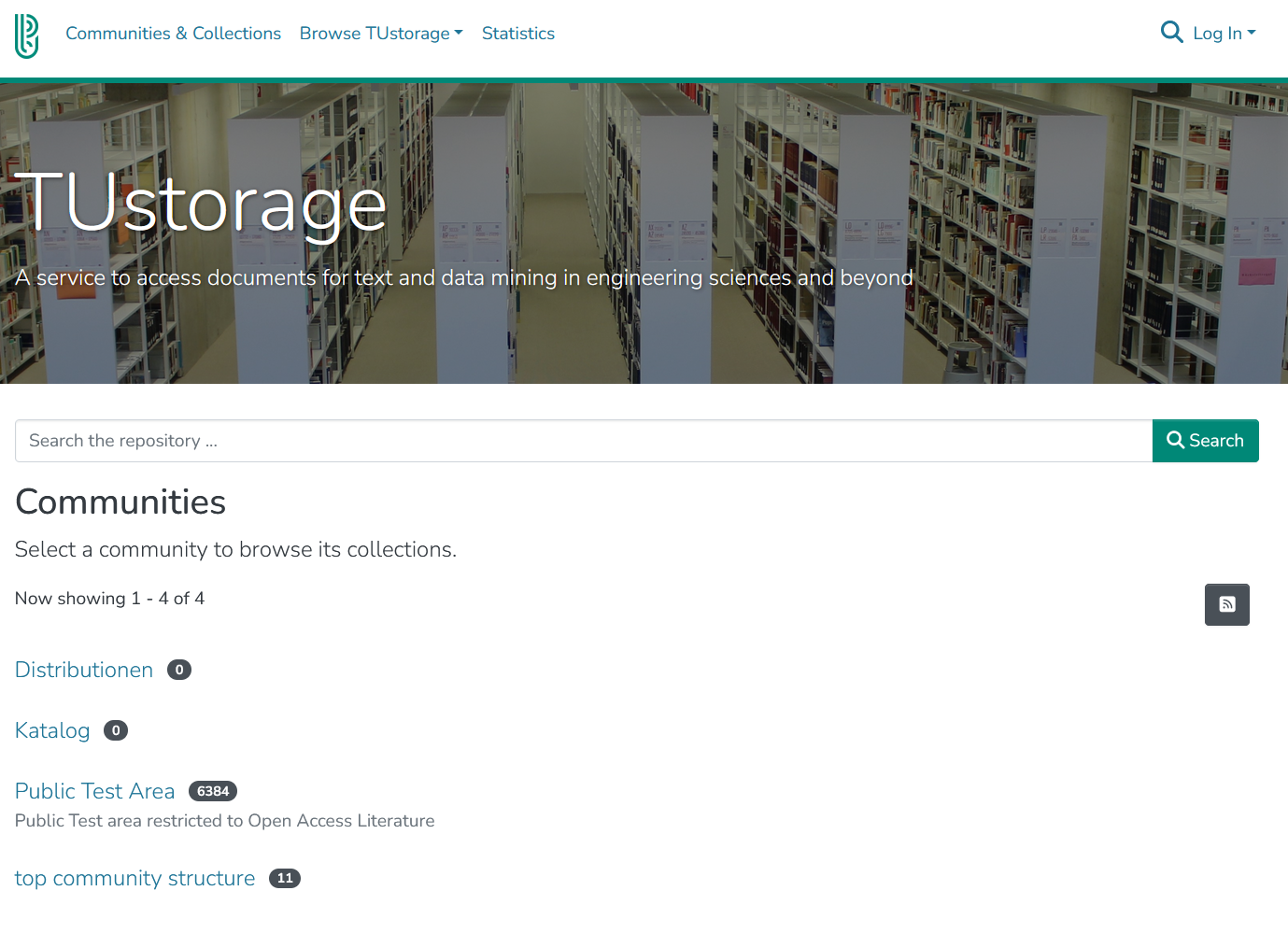
The repository is divided into a catalogue and a distribution area as shown in Figure 1. The catalogue area contains the metadata records of the documents, while the distribution area contains the actual full text files, which are usually available in PDF and XML format, where available together with image and supplementary information files.
TUstorage start page with distribution, catalogue and public test area
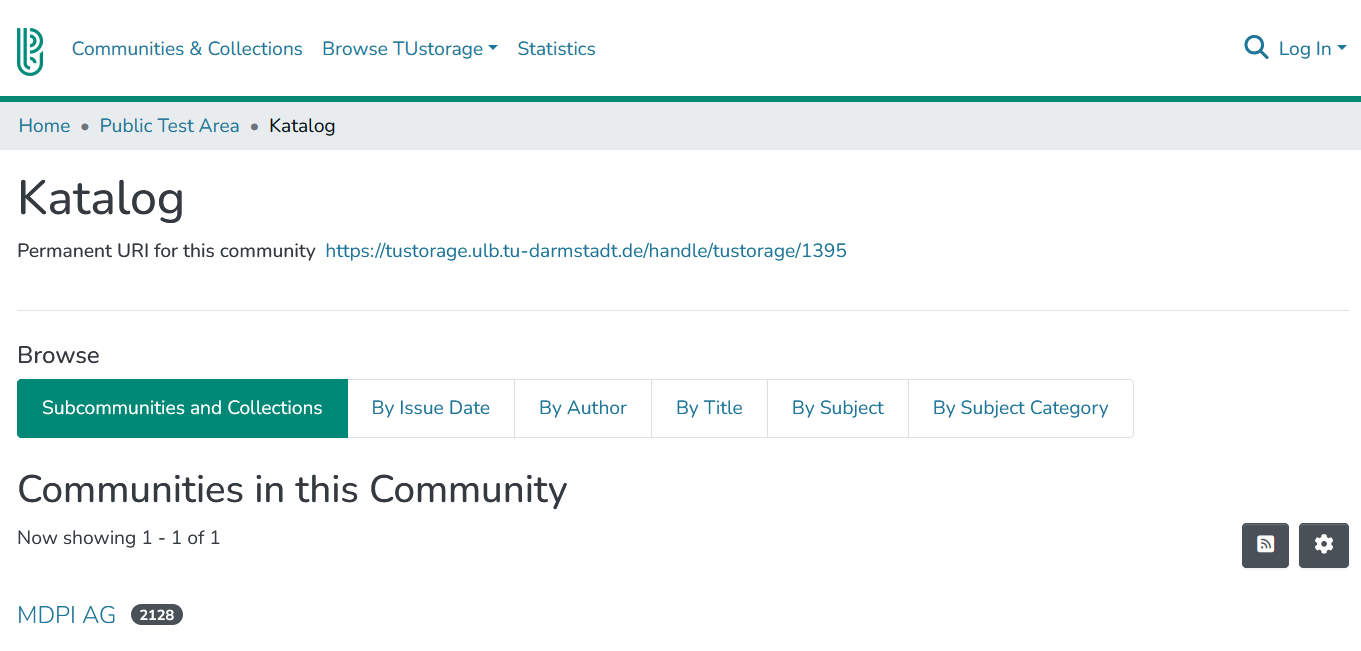
In the current test mode of the repository, all documents are located in the ‘Public Test Area’. Within this test area are two test sub areas ‘Distributions’ and ‘Catalogue’. Click on ‘Catalogue’ to display all publishers for which documents are available. The available journals are listed in the ‘Periodicals’ subsection (Figure 2), which in turn are subdivided into individual volumes.
Test Catalogue Area
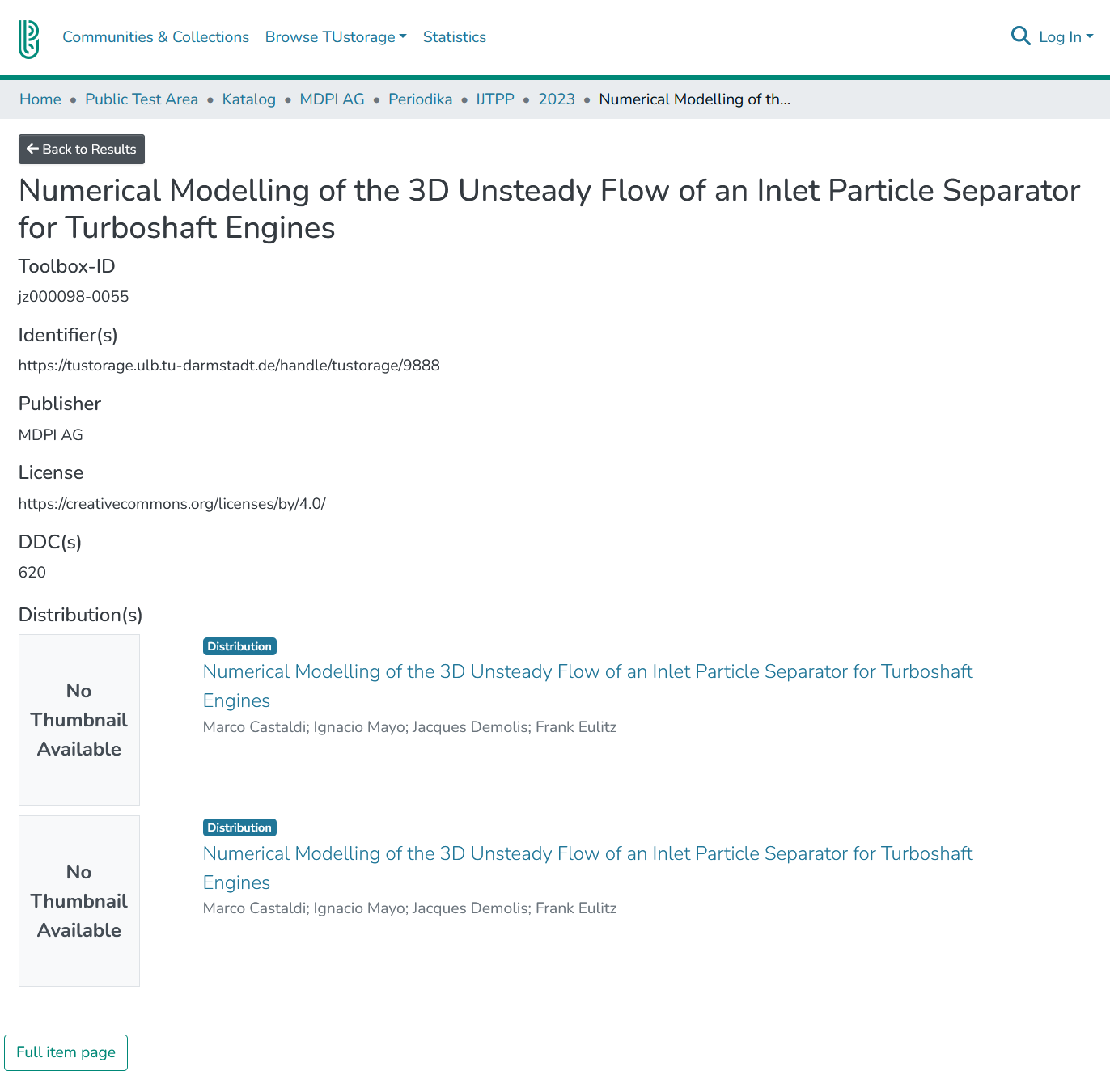
Each volume contains the journal articles’ metadata records in the form of ‘datasets’. In the lower part of the page, the available document versions, for example PDF or XML, are listed in the form of ‘distributions’ and can be downloaded from the linked pages of the distributions (see Figure 3).
The catalogue page of an example article with links to its distributions on the bottom of the page.
The added value of TUstorage is to enable users to download open access research literature in large amounts and in different file formats. TUstorage aggregates literature from different publishers and knowledge domains. All documents can be downloaded and used freely in the scope of their open access licences. Users no longer need to harvest literature from different publisher sources, e. g. websites, FTP servers, proprietary APIs or cloud storage locations, before beginning their text and data mining analyses but can rely on TUstorage as document source.
The service is suitable for individual researchers working on text and data mining projects as well as web services which benefit from the availablity of large amounts of literature, e. g. search engines.
Currently, the service is in test operation with only a limited, but continuously growing, amount of literature.
publications that reference (or report on using) the service
#WhyNFDI
Miscellaneous
Tags
NFDI4ING services may be relevant to different users according to varying requirements. To support filtering or sorting, we added a tag system outlining which archetype, phase of the data lifecycle, or degree of maturity a service corresponds to. By clicking on one of the tags below, you can get an overview of all services aligned with each tag.
The tags correspond to: The Archetypes: Services relevant to Alex – Bespoke Experiments, Betty – Research Software Engineering, Caden – Provenance Tracking, Doris – High Performance Computing, Ellen – Complex Systems, Fiona – Data Re-Use and Enrichment
The data lifecycle: Services related to Informing & Planning, Organising & Processing, Describing & Documenting, Storing & Computing, Finding & Re-Using, Learning & Teaching
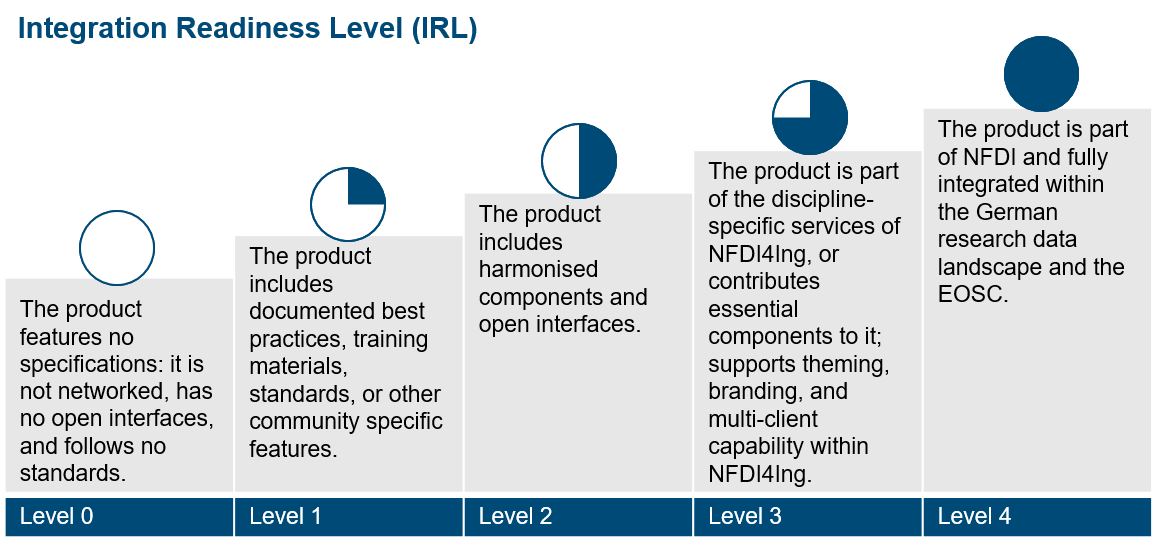
The maturity of the service: Services sorted according to their maturity and status of their integration into the larger NFDI service landscape. For this we use the Integration Readiness Level (IRL), ranging from IRL0 (no specifications, strictly internal use) up to IRL4 (fully integrated in the German research data landscape and the EOSC). Click here for a diagram outlining all Integration Readiness Levels.
{kind=link}