What does HOMER do?
One major factor of making data FAIR is the implementation of a controlled vocabulary with common terminology. Most of the research data in the HPMC domain is neither documented nor are metadata sets available, as common terminologies for HPMC in the engineering sector still need to be developed and established within the community. HOMER allows to automatically retrieve relevant research metadata from script-based workflows on HPC systems and therefore supports researchers to collect and publish their research data within a controlled vocabulary using a standardized workflow. The tool is designed to be flexible and adjustable to the user’s needs in its application and easy to implement in potentially any HPMC workflow.
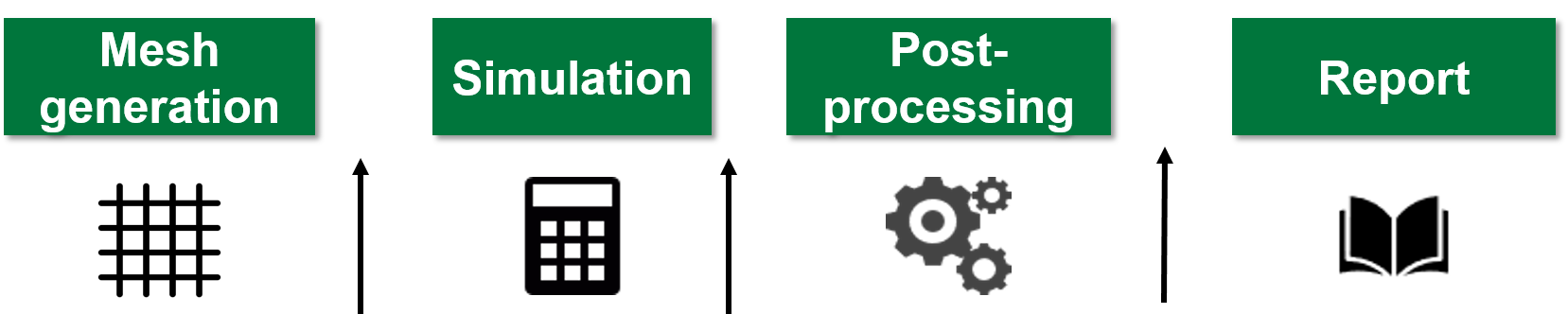
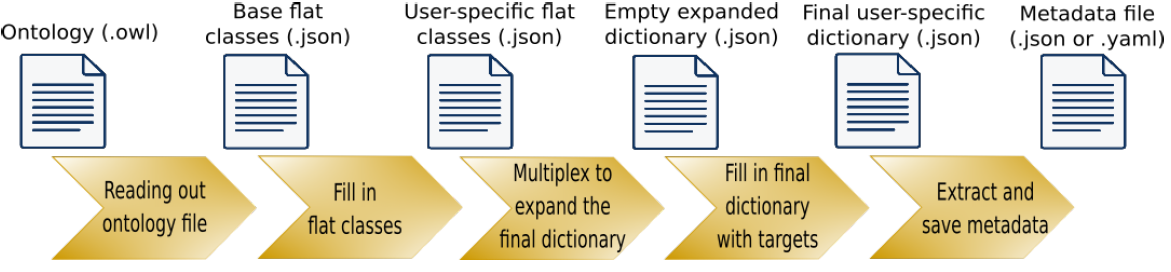
In fact, the crawler can retrieve metadata from text and binary (HDF5) files, as well as from user’s annotations and terminal commands, at any stage of the workflow without interfering with the other processes composing the workflow. The automated extraction of metadata can be performed both in edge as well as in central mode, making the tool suitable for extracting information also from central repositories (such as data lakes). The metadata extraction is based on the ontology schemes chosen by the users. However, the users do not need to strictly adhere to a fixed scheme, but can adjust and customize it according to their needs. Moreover, although developed primarily keeping engineering sciences as the main use application, HOMER can be employed to retrieve metadata from HPMC workflows applied to a wide variety of research fields. Once the first setup has been completed, the configuration file (created at the end of step four) can be re-used with little to no modification every time a new simulation is performed by the user and new metadata need to be extracted. This allows for a seamless integration of the tool within the workflow.
Finally, the tool has been written with a modular structure, so it can easily be developed further to include new features. When running the code for the first time, five steps are needed, with two of them requiring direct user input.
Hence, HOMER is proposed as a flexible and consistent RDM tool that can be used in a wide variety of applications and fields with limited user inputs in order to easily promote the FAIR principles and enrich the data created by the user.
Link to the service
Terms of use & restrictions
HOMER is available free of charge and maintenance and support are offered for at least the duration of the project. A GitLab account is required to participate in further development and to make full use of the repository.
Contact
References
publications that reference (or report on using) the service
From Ontology to Metadata: A Crawler for Script-based Workflows, https://www.inggrid.org/article/id/3983/