
The Task Area Doris designs transferable research-data management concepts and tools for data from high-performance measurement and computation (HPMC), enables, and supports the community to apply these solutions. In order to standardize and facilitate RDM for our peer group, we provide support for the complete data life cycle.

Metadata extraction
In order to standardize and facilitate RDM for our peer group, we provide solutions for the complete data life cycle. Every aspects of data management, starting from the planning period, should be documented in a data management plan, for example in the Doris template, which already includes an extension for data from HPMC. To collect metadata, especially in the stages of planning, creating/collecting and processing/analyzing, Doris provides the python-written metadata crawler HOMER (HPMC tool for Ontology-based Metadata Extraction and Re-use). It allows to automatically retrieve relevant research metadata from script-based workflows on HPC systems. The tool offers a flexible approach to metadata collection, as the metadata scheme can be read out from an ontology file. Through some limited user input, the crawler can be adapted to the user’s needs and easily be implemented within the workflow, enabling to retrieve relevant metadata. The obtained information can further be automatically post-processed. For example, strings may be trimmed by regular expressions or numerical values may be averaged. Currently, data can be collected from text-files and HDF5 files.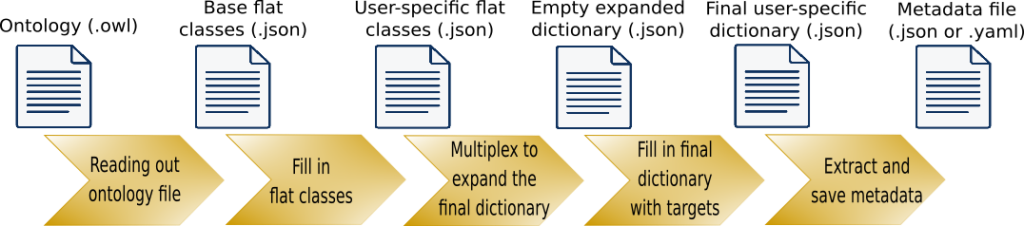
Fig. 1: The five steps the crawler is currently composed of and related input/output files.
© G. Chiapparino
Furthermore, the tool has been designed in a modular way, so that it allows straightforward extension of the supported file-types, the instruction-processing routines and the post-processing operations. A future step would be to cover the complete data life cycle in a holistic approach, by providing the possibility to automatically preserve and publish/share the extracted metadata along with the research dataset. Through publishing more than just the data like administrative (preservation) metadata, third party users will be able to retrieve crucial information about accessibility, access rights and licenses among others. Bibliographic (author, identifiers) and descriptive (research domain, tools, methods, processing steps) metadata can be published in repositories altogether with the referenced research data, or be linked to the research data by persistent links and identifiers, if technical or organizational impede a joint provisioning (e.g. if the research data is too large to be stored in a common repository). A detailed article regarding metadata crawling with HOMER is scheduled for the first issue of ing.grid – the journal for FAIR data management in engineering sciences.
Controlled Vocabularies and Findability
One major factor of making data FAIR is a controlled vocabulary / common terminology. Therefore, Doris provides a first, user-based concept for a HPMC sub-ontology within the framework of Metadata4Ing. The NFDI4Ing consortium is simultaneously working on a generic interface, which combines different kinds of metadata and data repositories with one standard-based interface (metadataHub), which could close the gap within the metadata toolchain from using common vocabularies and automatized extracting to FAIR publishing.
Community Support
The success of Doris’ measures depends on acceptance and usage of RDM concepts and tools within the HPMC community. To transfer the obtained knowledge and outcome, and to promote preexisting or newly developed tools, Doris regularly provides community-based training and workshops. In this context, we cordially invite all interested users to the upcoming Doris (online) workshop on March 28, 2022. The workshop is addressed at users of HPC computing centers producing large amount of (immobile) data and personnel in research-data management. Further information, registration and updates: Link.
The primary focus of Doris lies on the (national) tier 1 computing centers, but we are trying to establish an improved involvement of tier 2 centers or the NHR Alliance (National High Performance Computing). Therefore, we would like to invite scientists in RDM from tier 2 centers to contact us for future collaborations in infrastructure, data management or community support.
Contact
Spokesperson: Prof. Dr.-Ing. Christian Stemmer
Participants: TU Munich (TUM), High-Performance Computing Center Stuttgart (HLRS), Leibniz Supercomputing Centre (LRZ), RWTH Aachen University
Benjamin Farnbacher, TU München
Guiseppe Chiapparino, TU München
Vasiliki Sdralia, TU München
Christian Stemmer, TU München