

Metadata from High Performance Measurement and Computing (HPMC)
One major factor of making data FAIR is a controlled vocabulary / common terminology. The use of a controlled vocabulary is essential for findability, interoperability, and consequently, the re-use and the establishment of new user models. Most of the research data typical for the archetype Doris is neither documented nor are metadata sets available, as common terminologies for HPMC in the engineering sector still need to be developed and established within the community.
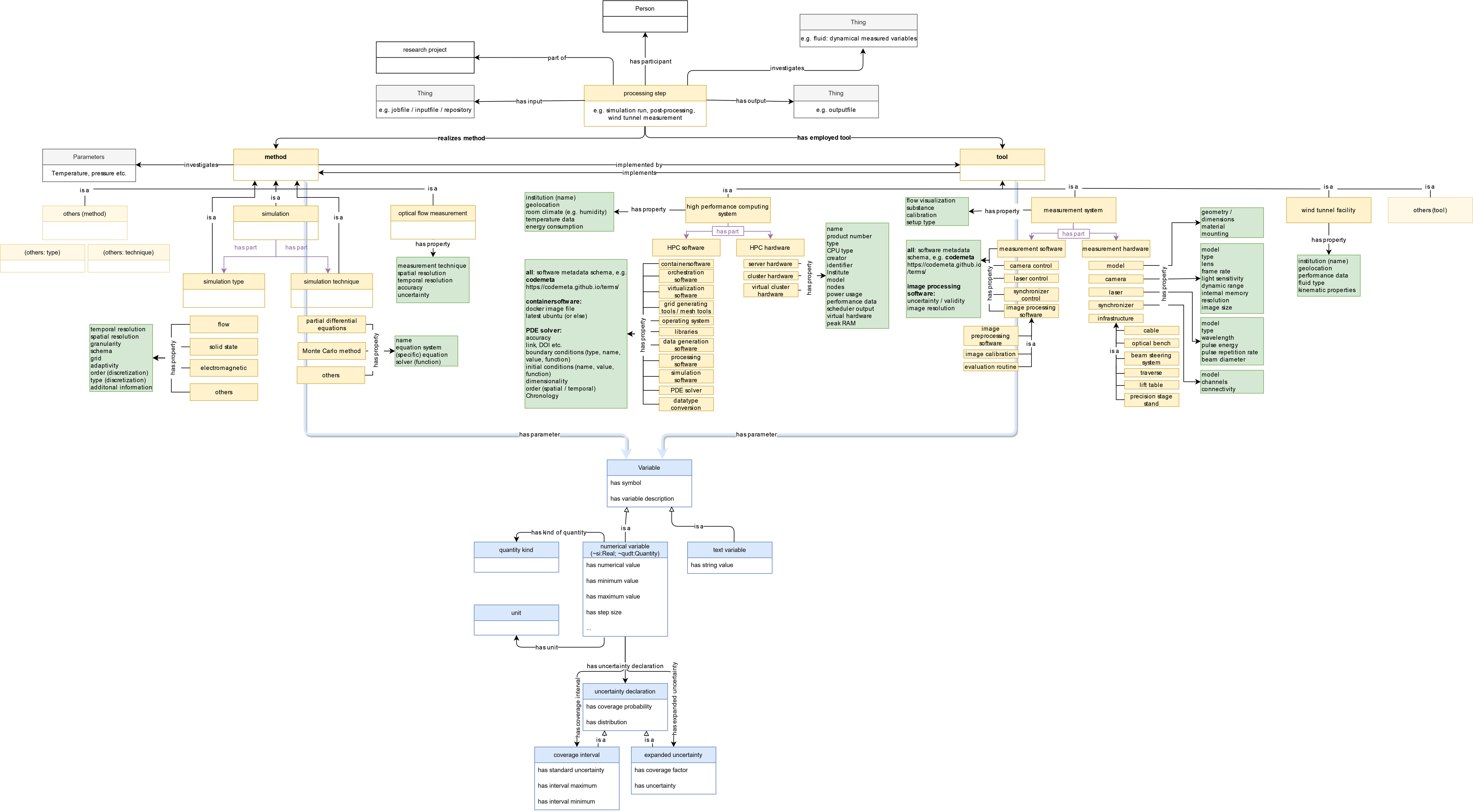
The consortium NFDI4Ing has developed an ontology as a common classification of engineering data in a taxonomic hierarchy with standardized vocabulary and procedures. Metadata4Ing aims at providing a framework for the semantic description of research data with a particular focus on workflows in the engineering sciences. This ontology allows a thorough description of the whole data-generation process (experiment, observation, simulation), embracing the object of investigation, all sample and data manipulation procedures, a summary of the data files and the information contained, and all personal and institutional roles. The subordinate classes and relations of Metadata4Ing are built according to the principles of inheritance and modularity. Inheritance describes how a subclass inherits all properties of its superordinate class, with the possibility of adding new ones. Modularity describes the independence of all expansions of each other; this enables for instance to generate expanded ontologies for any possible combinations of method × object of research.
Consequently, Doris provides a user-based concept for a workflow based HPMC sub-ontology within the framework of Metadata4Ing. The expansion to an HPC-sub-ontology is based on modularity and fits in the primary Metadata4Ing classes of method, tool, object of research. The expansion includes suggestions of unambiguous terms for domain related metadata expressed in classes, object properties (relations) and data properties. These classes have been developed in a community-based approach and represent common methods and tools for workflows in engineering research on HPMC systems.
{kind=link}
The terminology and definitions are mostly quoted from established vocabularies or newly determined. Of course, this terminology is subject to change, which is why we are open to suggestions for new classes and properties as well as improved terminologies. This semantic HPMC-metadata-set can easily be adapted to individual needs and allows for the expansion of additional vocabularies describing new workflows and investigated domains. The use of the Metada4Ing ontology and the HPMC expansion generates a data description in a single knowledge graph approaching the fulfilment of FAIR data principles for HPMC metadata. Especially the findability and interoperability of datasets is going to be substantially improved by a consistent and unambiguous terminology.
Call for contributions
An overview of Metadata4Ing is available at the ontology documentation. The ontology code is developed at m4i’s GitLab repository, where a special branch for the HPC expansion is publically available and open for contributions, comments and suggestions. We cordially invite all engineers in HPMC to apply the ontology and to contribute to further development with feedback, extensions, and suggestions for improvement via GitLab issues (or any other option to contribute): https://git.rwth-aachen.de/nfdi4ing/metadata4ing/metadata4ing/-/issues
To collect metadata, especially in the stages of planning, creating/collecting and processing/analyzing, Doris released the python-written metadata crawler HOMER (HPMC tool for Ontology-based Metadata Extraction and Re-use). It allows to automatically retrieve relevant research metadata from script-based workflows on HPC systems and fill it into any given ontology.
Outlook
The NFDI4Ing consortium is simultaneously working on a generic interface, which combines various kinds of metadata and data repositories with one standard-based interface (metadataHub), which could close the gap within the metadata toolchain from using common vocabularies and automatized extracting to FAIR publishing. This enables the linking between all data and metadata of the research-data life cycle, including experiments, raw data, software, subject-specific metadata sets, and the tracking of usage and citations. Standardized and automatically extracted metadata files can easily be made findable and accessible by this new generic interface.
To transfer the obtained knowledge and outcome, and to promote pre-existing or newly developed tools, Doris regularly provides community-based training and workshops. Please subscribe to our newsletter and participate in our workshops if you are interested in further guidance on how to use the sub-ontology and extract metadata using the HOMER script.
Contact
Doris newsletter
HPC metadata newsletter
General inquiries: info-doris@nfdi4ing.de
Website: https://nfdi4ing.de/archetypes/doris/
Spokesperson: Prof. Dr.-Ing. Christian Stemmer | christian.stemmer@tum.de
DORIS participants:
TU Munich (TUM)
High-Performance Computing Center Stuttgart (HLRS)
Leibniz Supercomputing Centre (LRZ)
RWTH Aachen University
B. Farnbacher
F. Ulrich
Ch. Stemmer