
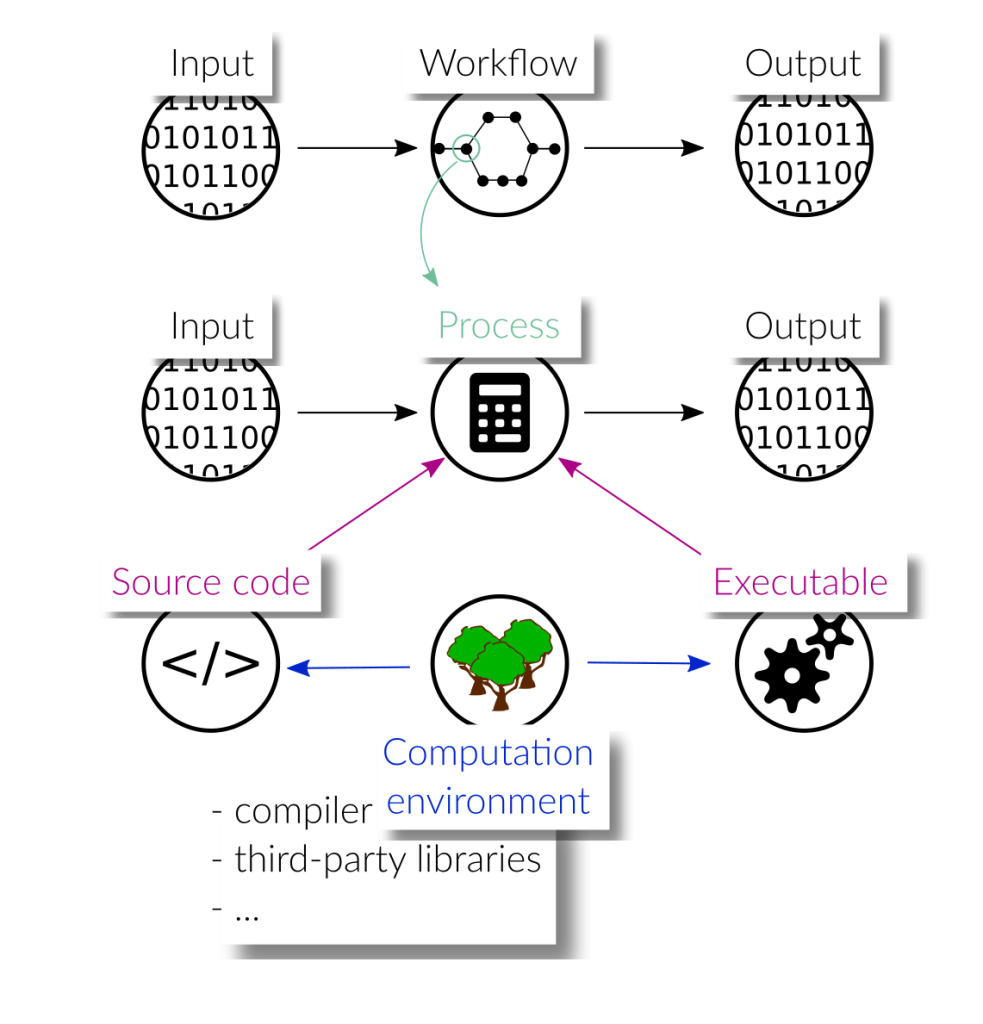
Illustration of a computational workflow and its dependencies.
Most of the tasks involved in (engineering) research today require the use of software for the generation, manipulation or visualization of data. Moreover, particularly in the engineering sciences, researchers often need to write their own code for very specific tasks that are not covered by out-of-the-box solutions. With advancements in science, the tasks to be performed tend to become more and more complex and correspondingly require complex software solutions that cannot feasibly be implemented from scratch within a single PhD thesis. For this reason, it is of major importance that existing research software can be found, reused and/or maintained to allow for incremental development processes. In the NFDI4Ing task area Betty we are working on solutions to help researchers with these aspects. In the following paragraphs, we present some of our more recent efforts.
Teaching Material
Good software development can be aided by tooling, but ultimately, the software quality is strongly dependent on the skillset of the developers. Therefore, we have compiled a set of teaching material related to software development ranging from version control, testing, continuous integration to design principles and patterns. This material aims at providing easy entry points into these topics for people who are not yet experienced software developers, with links to more detailed material for those who are interested in further reading. We have also curated some of this material into a 4-days intensive course including exercises available here.
Software quality assurance
Testing is a corner stone of good software development, since it is the tool that allows us to guarantee our software works. Many researchers in the engineering sciences use or develop code for simulations, which produce data such as temperature or pressure fields in the simulated domain. For such code bases, regression tests provide an efficient and easy way of testing the software by using small simulations as tests, comparing the results against trusted reference solutions. To make it easier for researchers to use this technique, we have developed a Python framework that provides the tools required to compare simulation results in a wide range of file formats. Besides this, we are currently working on a software library that provides a lightweight API that enables users to write their simulation results into widely-used standard file formats.
Finding research software
The findability of research software often depends on the willingness of researchers and scientists to publish the results of their work that go beyond the written explanation (such as found in papers, articles, technical reports etc.) and referencing them accordingly. Promoting a novel approach or an improvement of an existing method without providing the source code that was used to perform the research, means a greater effort for every researcher down the stream that wants to utilize the described research software. Moreover, the process of finding research software for a specific purpose is inefficient. Most often, one must look through a publication before being able to hope for a corresponding link to a repository where the research software is being stored. This way of searching also does not allow applying preferences (e.g., only searching for research software written in Python).
To address this problem the task area Betty is working on finding new ways of searching for research software more efficiently. Betty‘s (re)search engine for instance, is a novel approach that performs a “cascading search” in which we start off by searching for software repositories on platforms like GitHub and then try to find corresponding publications for each of the repositories we found. This novel approach enables users to sort the repositories based on their number of citations and therefore relevance in their research community. We envision this tool in the hands of researchers corresponding to Betty to make research software more FAIR.
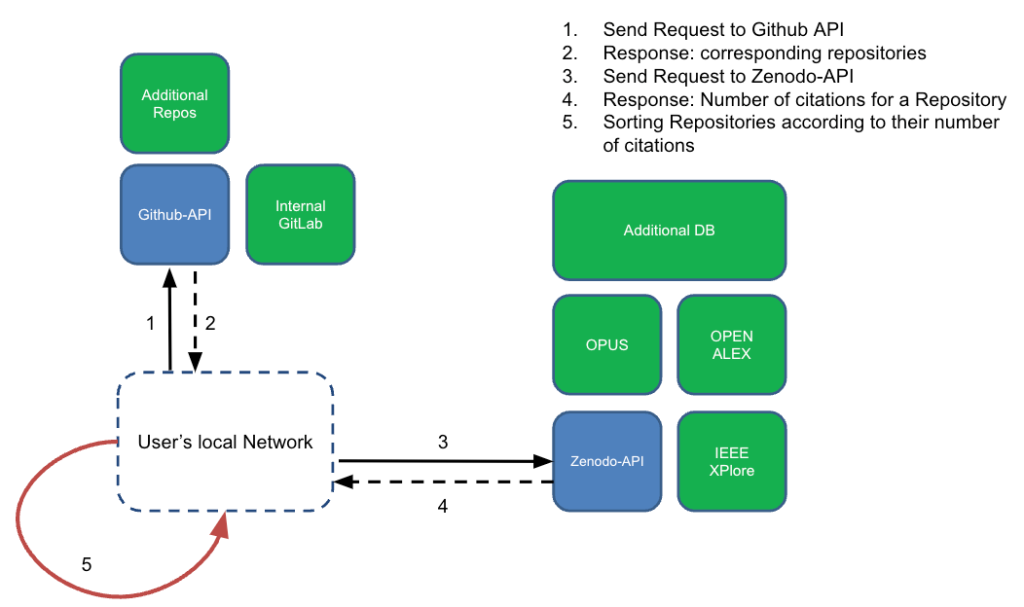
Illustration of the architecture of Betty's (re)search engine
Reproducible research workflows
Research often involves a series of different tasks, performed by different pieces of software that are executed in a particular order, while passing the data produced by one task as input to a subsequent task. Ideally, such a computational workflow is fully automated without requiring any manual steps in between. This makes it much easier to reproduce results obtained today at a later point in the future. In a currently ongoing project, we are evaluating a number of existing workflow tools regarding their suitability to automate scientific computational workflows. The tools are evaluated with respect to different criteria such as ease-of-use, composability, capabilities of encapsulating the required software environments, and support for HPC (High-Performance-Computing) environments. An exemplary workflow, which is representative for research that involves simulations, has been created and realized with the tools that were selected for this comparative study. The implementation and documentation of this study can be found here. We hope that this documentation helps researchers to identify the tools that are best suited for their use case.
Call for participation
Like all archetype-related task areas in NFDI4Ing, Betty follows a bottom-up approach by means of implementing pilot use cases together with partners from several areas of the engineering sciences. We are always keen on identifying new use cases and encourage every engineer interested or already involved in research software development to contact us and participate: betty@nfdi4ing.de.
D. Gläser