
Manual development and maintenance of ontologies are tedious tasks and require extra training to use ontology modelling tools. Therefore, a semi-automatic process to enrich ontologies can assist domain experts, who are not necessarily ontology experts, to map knowledge into ontologies. OntoHuman pursues a Human-in-the-Loop (HiL) approach to address this, which requires humans to provide feedback to an automated system for information extraction from technical documents.
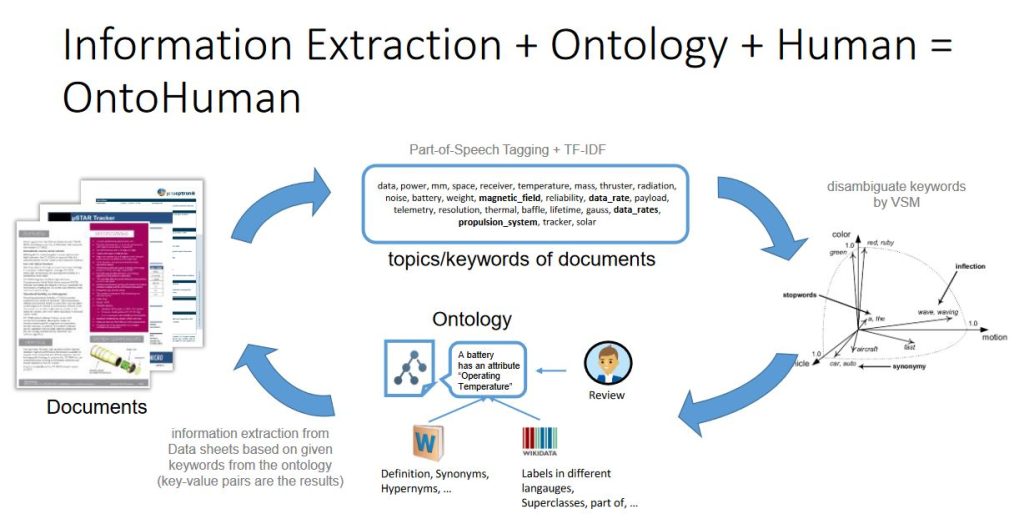
Illustration of the basic concept of OntoHuman
The project OntoHuman set out to address and support two purposes: to enrich ontologies, which contain semantic information describing objects or concepts, and to extract information from technical documents (e.g. to enrich ontologies with this information).
Manual development and maintenance of ontologies are tedious tasks and require extra training to use ontology modelling tools. Therefore, a semi-automatic process to enrich ontologies can assist domain experts, who are not necessarily ontology experts, to map knowledge into ontologies. Major sources of information for enriching ontologies are often documents, especially data sheets in engineering domain. These data sheets are used during the planning and designing of products and they are crucial for choosing components that fulfil project requirements. However, the information in data sheets are mostly not accessible in machine-readable formats. In current practice, they are manually extracted and converted to be compatible to computer applications.
OntoHuman builds on prior work by members of the Institute of Data Science at the German Aerospace Center (DLR) who already developed prototypical solutions for automatic information extraction from technical documents with the support from ontologies [1]. To verify the results of an automatic process, they pursued a Human-in-the-Loop (HiL) approach, which requires humans to provide feedback to the system. In this NFDI4Ing SeedFund project, the idea was to combine the HiL component with the available Data Sheets Annotation Tool (DSAT) to generalize the automatic information extraction process, which is running on the backend. Prior to this project, DSAT could only be used for space engineering related documents. Now it can apply and customize ontologies used for extracting data from documents of other domains. Feedback from users can also be collected via a web-based user interface and used for updating ontologies further, which could, in return, ultimately improve the automatic process. The source code for the OntoHuman software is published on Zenodo.
OntoHuman is the first project funded in the NFDI4Ing seed fund programme to present its results. The NFDI4Ing Seed Funds are designed to continuously develop the consortium’s work programme and adapt it to the needs of the engineering community. Funded projects support or extend activities of our archetype or base services task areas. OntoHuman is no exception. There are promising synergies with Base Services measure automated data & knowledge discovery in engineering literature (S-7), whose goal is to make engineering literature available in a standardised XML format for text and data mining applications:
- PDF documents harvested in Task S-7-1, originally intended only for further processing in the standardised XML format, could be made available directly to users of an OntoHuman installation as a data basis. Via the delivery system planned in S-7-1, users of an OntoHuman instance would be able to access harvested PDF documents and annotate them within the OntoHuman system, within the limits of the permissible licensing options.
- The information extraction module PLIX of the OntoHuman system can possibly be extended in such a way that it converts metadata from PDF documents into XML formats. Conceivable possible formats would be, for example, Dublin Core or TEI (Text Encoding Initiative). However, such a conversion is not yet implemented and would have to be developed first. The resulting metadata could then be uploaded to the S-7-1 delivery system, improving the discoverability of those PDF documents for which no metadata is available from other sources, which would be a very valuable contribution to Task S-7-1. The OntoHuman project and Task S-7-1 will exchange ideas to explore the possibility of further cooperation in this area.
The extraction of machine-usable information from text documents is also highly relevant for the scope of customised experiments, which corresponds to our task area Alex (especially Measure A-5). Even though the reuse of the ontologies generated or enriched by OntoHuman for now remains questionable or challenging (e.g., integration via the terminology service), the support or partial automation of the extraction of information is in itself an important contribution with high reuse potential. Further testing of the corresponding features is required, especially on the basis of case studies from the professional communities. A possible example from Thermal engineering and process engineering (CC-42) is the optimisation of the topology and operation of fluid systems, for which the required information about system components is currently transferred manually.
References
[1] Opasjumruskit, K., Schindler, S., Schäfer, P. M., & Thiele, L. (2019). Towards Learning
from User Feedback for Ontology-based Information Extraction. DI2KG ↩
K. Opasjumruskit
D. Peters
edited by T. Schwetje