Base Service “Research software development”: advice and services for good software
The base service "research software development" provides infrastructure, best practices and templates to make research software and its development more replicable and reproducible while improving the quality of the written code. Currently, our main projects are a JupyterHub server for the NFDI4Ing-community, a knowledge base with best practices and examples for sustainable code development, and training courses for, e.g., GitLab.
The NFDI4Ing Base Service “research software development” (S-2) provides infrastructure, best practices and templates to make research software and its development more replicable and reproducible while improving the quality of the written code. Currently, our main projects are a JupyterHub server for the NFDI4Ing-community, a knowledge base with best practices and examples for sustainable code development, and training courses for, e.g., GitLab.
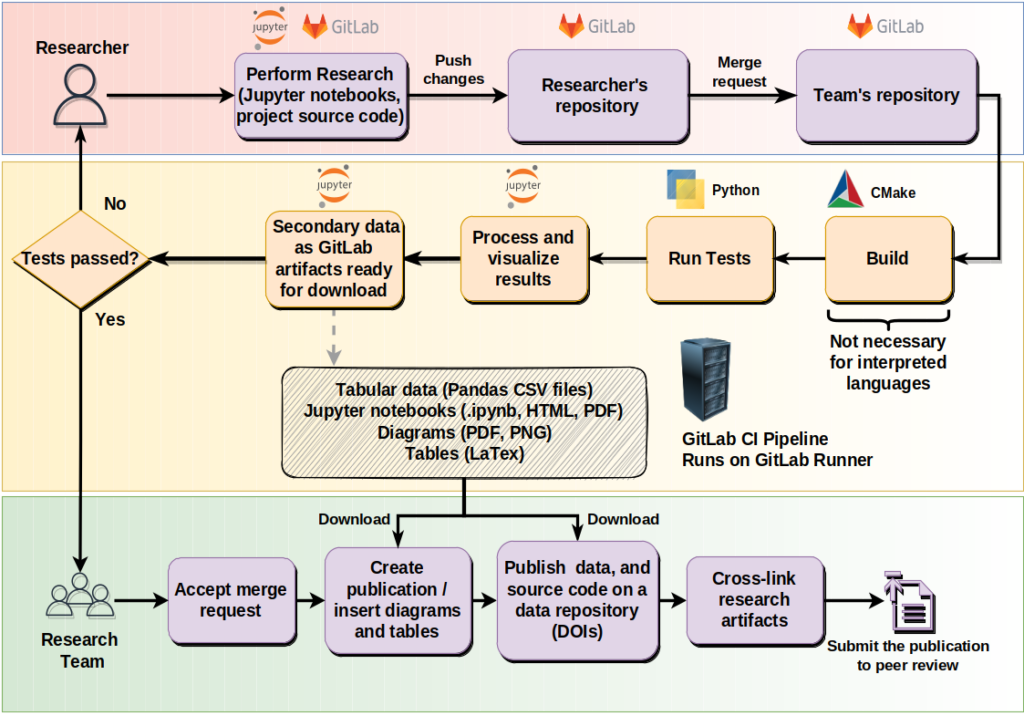
A research software engineering workflow.
Vision
Research software plays a fundamental role in the advance of science. Not only is every simulation based on code and the assumptions in the models therein, but also almost every measurement is evaluated using software. Therefore, the importance of functioning, quality-assured code and the effectiveness and effectivity of its development can hardly be over-emphasized. We dream of a world, where every piece of code is well-tested, quality-assured and easily reusable.
Reusable Workflows and Best practices
As one of our services we are providing a Knowledge Base for software development (accessible at knowledge-base.nfdi4ing.de). Here we provide various guides and “How-to”-articles on different topics of research software development. The workflow proposed and the articles provided have been developed and proven useful in the CRC1194 at TU Darmstadt, effectively combining version control, continuous integration, automatic testing and evaluation, both small-scale and with HPC-systems. The Knowledge Base is an ongoing project, in which we are working together with participants in- and outside of NFDI4Ing. We also actively engage in various training formats.
To support parallel code development and documentation, but also to make reproducing analyses easier, we have set up a JupyterHub that allows scientists to develop or reuse Jupyter notebooks. In these, code can be executed interactively and enriched with text, figures and more (literate programming).
Within two use cases, we provided MATLAB (the normal IDE, but also a dedicated kernel) for academic usage and made polyglot notebooks possible, i.e., notebooks which contain more than one programming language.
Currently, the NFDI4Ing JupyterHub is still in the testing phase and access to it a bit cumbersome. But we are working on simplifying that and offering a scalable service for as many users as possible.
Tomislav Maric Christian Bischof Moritz Schwarzmeier Anett Seeland