
As part of our ongoing efforts to connect with the engineering community, we asked our task areas to describe their target audiences and provide user stories that illustrate how NFDI4Ing can help to improve their Research Data Management (RDM).
To kick off this format, meet Doris, an engineer conducting and post-processing high-resolution and high- performance measurements and simulations on High-Performance Computing systems (HPC).

Background
Doris is an engineer conducting and post-processing high-resolution and high- performance measurements and simulations on High-Performance Computing systems (HPC). According to statistics from the tier 1 HPC centres in Germany, she has a background in material science, mechanics and constructive mechanical engineering, or construction engineering, with the (by far) most prominent background being heat energy technology, fluid mechanics and thermal machines.
The HPC background mandates tailored, hand-made software, which takes advantage of the high computational performance provided.
Challenges – how to get HPC data FAIR?
Accessibility
The data sets that are collected and processed by Doris are extremely large (hundreds of Terabyte or even Petabyte) such that they are, on the whole, immobile. They are too large to be copied to work stations, and the (post-) processing of the experimental and computational data generally is done on HPC systems. Usually, these data are not accessible to third parties due to the lack of local access models at HPC centres and because they are too large to be published in state-of-the-art repositories.
In a first, local proof of concept NFDI4Ing managed to publish a dataset produced and stored at the Leibniz Supercomputing Centre (LRZ) through a university repository (MediaTUM), managing the access rights through a virtual research environment (TUM Workbench).
The transfer of such large datasets can be facilitated and accelerated through to the installation of Globus Online endpoints. To enable the accessibility and reuse of large datasets directly at HPC centres, and therefore to test and establish new user models, we are implementing a new cloud-server system directly embedded into the infrastructure of LRZ in order to make HPC research data usable by external parties. Access can be set individually via virtual machine or microservice (e.g.DFN-AAI etc.). Direct integration into the data storage infrastructure of the data centre means that both “hot” and “cold” HPC research data can be accessed.
Documentation
Most of Doris‘ research data is neither documented nor are metadata sets available, as common terminologies for HPMC in the engineering sector still need to be developed and established within the community. Therefore, NFDI4Ing provides a first, user-based concept for a workflow based HPMC sub-ontology within the framework of Metadata4Ing (https://git.rwth-aachen.de/nfdi4ing/metadata4ing/metadata4ing).
The use of a controlled vocabulary is essential for findability, interoperability and consequently the re-use and the establishment of new user models. To collect metadata, especially in the stages of planning, creating/collecting and processing/analyzing, we released the python-written metadata crawler HOMER (HPMC tool for Ontology-based Metadata Extraction and Re-use). It allows to automatically retrieve relevant research metadata from script-based workflows on HPC systems (https://gitlab.lrz.de/nfdi4ing/crawler).
The NFDI4Ing consortium is simultaneously working on a generic interface which combines different kinds of metadata and data repositories with one standard-based interface (“Metadata Hub”). This enables the linking between all data and metadata of the research data life cycle, including experiments, raw data, software, subject-specific metadata sets, and the tracking of usage and citations. Standardized and automatically extracted metadata files can easily be made findable and accessible by this new generic interface.
To transfer the obtained knowledge and outcome, and to promote pre-existing or newly developed tools, NFDI4Ing regularly provides community-based training, workshops and established an undergraduate module on RDM in engineering sciences.
Why use RDM? Value added!
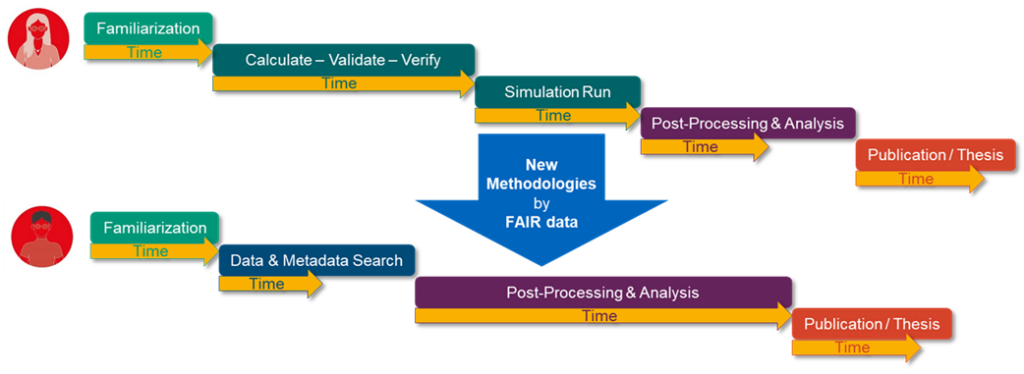
In the current state of the art, there are barely any data sets from HPMC that can be considered FAIR. We want to bring the general benefits of RDM to our community (e.g. improved visibility and reputation through published data sets) by offering appropriate tools, concepts and support. Apart from fulfilling funder’s requirements or scientific criteria (e.g. DFG Codes of Conduct), we are enabling new findings, new workflows and new cooperation opportunities by the re-use of existing data. Apart from the global visions for a new methodology, we create advantages in the operational research work.
Every researcher who applies our RDM tools and concepts for FAIR data also reaps benefits in internal data and project management. The right tools minimize the risk of data loss, increase the possibilities for data and knowledge transfer, and enable the verification and validation of proper models by the use of external data and software.
Researchers can already publish their HPMC data sets using our metadata schema and metadata crawling software. The corresponding metadata and metadata schemas can be published and linked to the research data once the Metadata Hub enters the required technology readiness level. By making HPMC research data FAIR, we are enabling a new user model respectively new methodologies for engineers working on HPMC systems. Being able to find, access and re-use existing, interoperable data, creates the possibility of doing post-processing and analysis on existing data rather than going through cumbersome proposals for computing time at HPC centres, and could shorten the time period from familiarization with a research topic to an actual tangible result (see Fig. 1).