RDM for RDM infrastructure?
NFDI4Ing’s work units, archetypes, and base services are working diligently on projects and ideas, generating deliverables and reports, writing news articles, and giving presentations. At our first annual project meeting, some questions well-known to research project managers surfaced: “How can the results be organized? How can connections and links be shown? How can interested parties learn about our results and services?” In NFDI4Ing, we are working on applying the best possible research data management to answer these questions.
The starting point – chaos before RDM
We have a SharePoint and RocketChat, we have a GitLab instance and project management tool, a website with a community hub, a newsletter, multiple mailing lists, Twitter, soon a journal and lists with contact persons in all working units – there should be no problem distributing the important information about a result or service to all stakeholders in the consortium and our community, right? The short answer: Not without a lot of manual work by dedicated personnel in each unit.
Again, many of the central questions already seem familiar to researchers: What is the important information? What is the right structure for the information? Where can we find prior results and documentation or instructions?
Approaching a solution
To support our knowledge management, ultimately, we want a (partly) machine-readable description, metadata scheme, and a consistent structure for our internal documents. However, it should not be too complicated and still human-readable. Our results are intended for humans, for the time being, the machine should only help us with structuring the information and making it accessible.
Measure CC-1 (Initialisation of communication services) is developing an approach to creating a catalogue from individual documents. This is already in use with Markdown and static site generators. One example from our Base Service Research Software Development is the NFDI4Ing Knowledge Base. Using keywords and chapters (amongst others), both automatic and manual (hierarchical) structures can be created.
However, the notes are so far limited to a single GitLab repository where all documents must reside. The website is created using Continuous Integration (CI) methods. More information on this can be found, for example, in the Knowledge Base in chapter 2.5. The automation steps described below are implemented using CI methods as well.
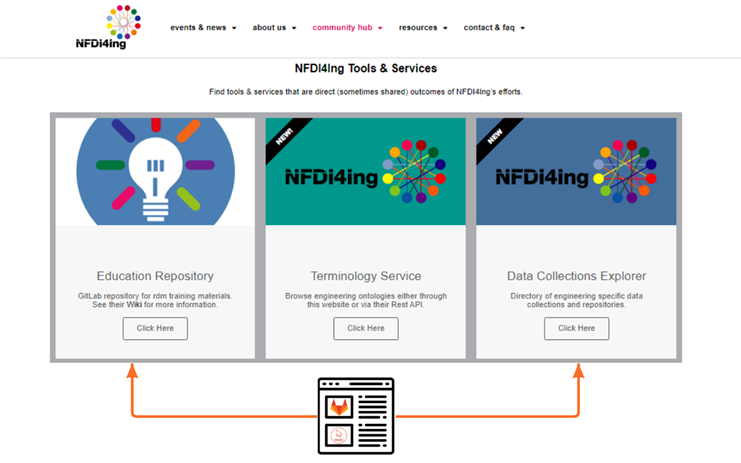
Sort, Collect, Distribute
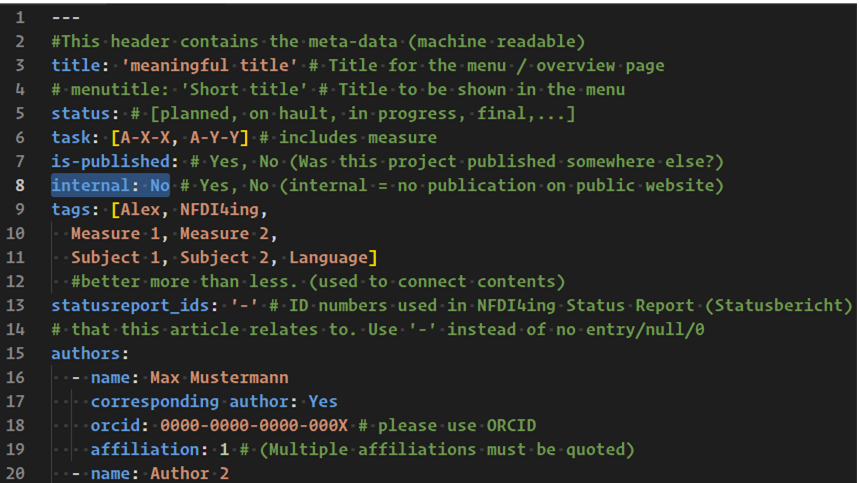
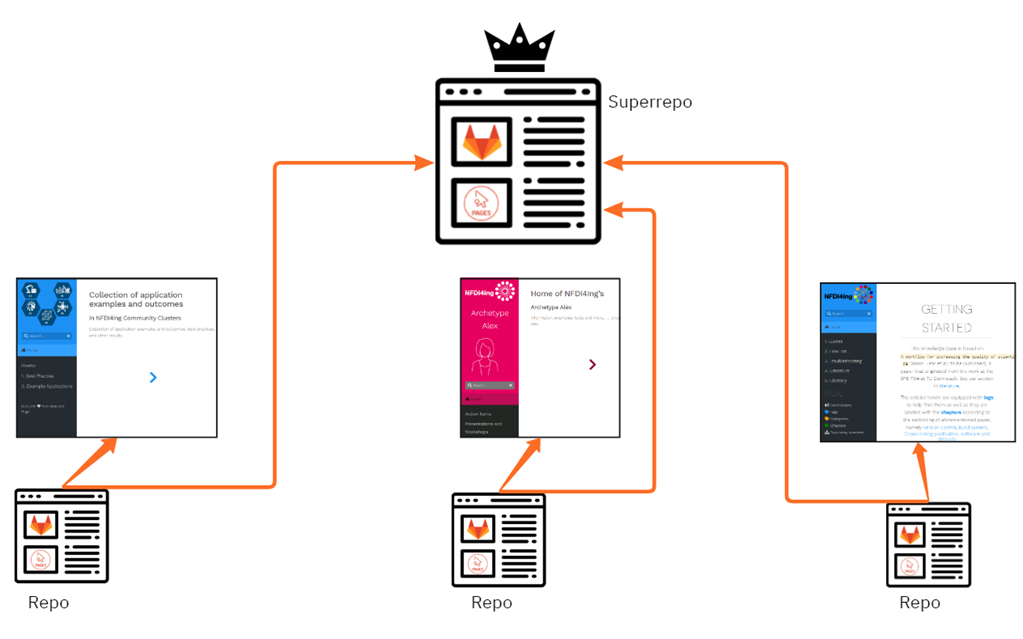
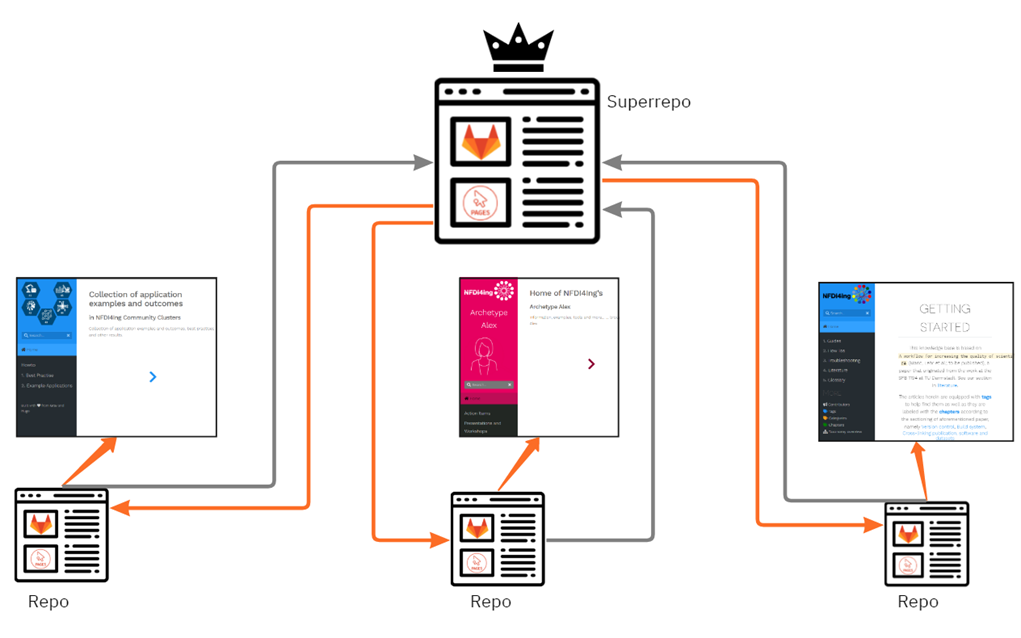
In a collaboration with the task area ALEX, two interacting repositories and catalogue websites have been created. To start, documents are created or filed in the first repository. There, a non-public preview (web page) of all documents is created automatically. Machine-readable information is stored in the document’s header (e.g., the author, title, and attribution of the document, and whether it should remain internal or can be published):