
SciMesh is Caden’s RDF graph topology to map scientific results onto a knowledge graph. In Caden, we use SciMesh as a standard to map content of an ELN to a data format that can be read by other ELNs. An unsolved problem has been how to deal with processes that involve more than one specimen, or with subprocesses. We addressed this problem by adding so-called “concurrents” to SciMesh.
Ideally, scientists working in a collaboration can easily import data across different ELNs, and visualise the insights generated by their remote peers merged with their own local data. In Caden, we use SciMesh as a standard to map content of an ELN to a data format that can be read by other ELNs for visualisation of that external data.
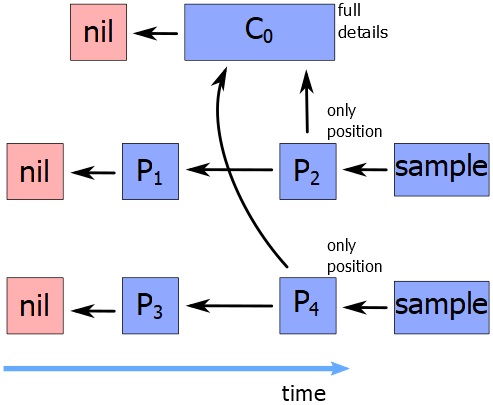
SciMesh relies on the concepts of cause-effect relations and well-defined (intermediate) states of specimen and data. The central entity class is that of a process that represents both some form of action (mostly an experiment) and the state it leads to. However, this causes problems in the case of compound processes, where many samples have been processed in the same experiment.
We experimented with different topologies to address this problem and ended up with so-called “concurrents”. A concurrent is a special kind of process that does not end in a well-defined state. Instead, it is well-defined only together with its subsequent processes. This can realise compound processes (as well as some other special cases) very simply and effectively.
Concurrents already have a reference implementation in JuliaBase. If you want to kick the tires, you can read up on the implementation in the explainer provided here.
We are very keen to hear your opinion about that and the other aspects of SciMesh and the endeavours of the task area Caden. If you want to comment or contribute, please contact caden@nfdi4ing.de.
SciMesh relies on the concepts of cause-effect relations and well-defined (intermediate) states of specimen and data. The central entity class is that of a process that represents both some form of action (mostly an experiment) and the state it leads to. However, this causes problems in the case of compound processes, where many samples have been processed in the same experiment.
We experimented with different topologies to address this problem and ended up with so-called “concurrents”. A concurrent is a special kind of process that does not end in a well-defined state. Instead, it is well-defined only together with its subsequent processes. This can realise compound processes (as well as some other special cases) very simply and effectively.
Concurrents already have a reference implementation in JuliaBase. If you want to kick the tires, you can read up on the implementation in the explainer provided here.
We are very keen to hear your opinion about that and the other aspects of SciMesh and the endeavours of the task area Caden. If you want to comment or contribute, please contact caden@nfdi4ing.de.
Torsten Bronger, FZJ, ORCID 0000-0002-5174-6684