The NFDI4Ing task area Betty envisions a future in which the engineering sciences produce validated, high-quality software that can be reused and extended. Betty follows a bottom-up approach and we are always keen on identifying new use cases!
Most of the tasks involved in today’s research require the use of software for the generation, manipulation or visualization of data. Moreover, particularly in the engineering sciences, researchers often need to write their own code for very specific tasks that out-of-the-box solutions do not cover. With advancements in science, the tasks to be performed tend to become more and more complex and accordingly require complex software solutions that cannot be feasibly implemented from scratch within a single PhD thesis. For this reason, it is of major importance that research software can be reused and/or adapted to allow for incremental development processes.
This comes with a number of challenges: First, developing complex, flexible and reusable software is no trivial task, and the typical engineering curricula today do not sufficiently cover important aspects of software engineering, such as software design principles or quality-assurance measures. Second, it has to become standard practice to publish the source code used for the generation of results reported in scientific works. Additionally, for the published code to be of real use for other researchers, the software has to be properly documented and the detailed requirements on the hardware and software environments have to be stated. Finally, other researchers have to be able to find the software when searching for keywords that describe the problem they are trying to solve.
We believe that computational research could benefit from the following practices related to software:
- Use version control for every bit of code used in research activities.
- Write tests for all code to guarantee its correctness.
- If existent, test the code against established benchmarks to guarantee the validity of the results.
- Whenever possible, use established open-source packages for algorithms and functionality you need in your research instead of reinventing the wheel.
- Use well-established and widely used data formats for any data your software produces.
- If your research involves multiple steps of data processing with different software tools, automate the execution of these steps and publish this automation alongside with your paper, data and code.
In the task area Betty, we are working on solutions to help researchers with these aspects. To this end, we are currently compiling a condensed set of teaching material and tutorials on different aspects of software engineering. This material is designed with a focus on topics and heuristics shown to be useful in research-related activities and is meant to serve as a high-level and easy-to-access starting point for interested researchers.
Software quality assurance
The most useful way of guaranteeing functional software is by continuously testing it against every change made. These tests can range from unit testing individual functions to testing the entire system as a whole. Many researchers in the engineering sciences use or develop code for the simulation of physical processes, which produce data such as temperature or pressure fields in the simulated domain. For such code bases, regression tests provide an easy means of testing the software by using small simulations as tests and comparing the results against reference solutions that were obtained beforehand. In order to facilitate researchers to use this technique, we are currently developing a fully customizable Python framework that provides the tools required to compare simulation results, and which already supports a wide range of standard file formats. At the same time, we are working on a small software library that researchers can use to transcribe the field data obtained with their own methods and data structures into these standard file formats. It is important to note that regression testing only ensures that the software produces the same results over time, but the results may still be wrong. For verification purposes, the simulation results have to verified against benchmark solutions. To do that, researchers have to be able to find related reference data or software.
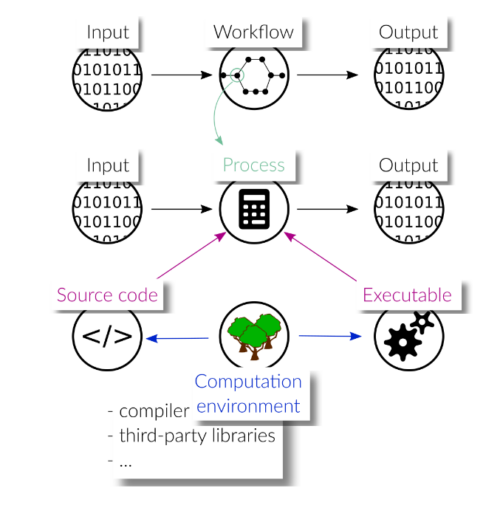
Illustration of a computational workflow and its dependencies. Each task of the workflow is represented by an executable and the associated source code, while it may pose additional requirements on the software/hardware environment.
Finding research software
Another effort in the task area Betty is the development of a query service for open-source software that may be useful in research. To this end, we plan to scan paper and software archives to find linked textual and code publications, and then extract domain-specific information to be attached to the results. This can then allow researchers to search for (research) software by means of search strings that contain problem-specific language, e.g. a certain algorithm, a mathematical method or a whole field of research.
Reproducible research workflows
As mentioned before, research often involves a series of different tasks, performed by different pieces of software that have to be executed in a particular order, passing the data produced by one task as input to a subsequent task. In order for research to be reproducible, it is beneficial if this workflow is automated and published alongside with the rest of the code and any data that is required to execute it. In a comparative study, we are currently evaluating a number of workflow languages and tools, focusing on measures such as ease-of-use, composability, capabilities of encapsulating the required software environments and support for HPC (High-Performance-Computing) environments. The comparison is done by means of exemplary workflows that test for requirements that are typical in research, and the entire process including the documentation is fully open-source and available at https://github.com/BAMresearch/NFDI4IngScientificWorkflowRequirements. As a result, we hope to be able to provide recommendations on how to use existing workflow tools and languages to reach our goal: reproducible research workflows, by anyone, anywhere and anytime.
Call for participation
Betty follows a bottom-up approach by means of implementing pilot use cases together with partners from several areas of the engineering sciences to further our programme. We are always keen on identifying new use cases and encourage every engineer interested or already involved in research software development to contact us and participate: betty@nfdi4ing.de.
B. Flemisch, D. Gläser